

欢迎在文章下方评论,建议用电脑看
注意,需要明白recurrent neural network和recursive neural network之间的区别!
在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能无力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。这个时候,我们怎么办呢?下面有两种解决方案
在每轮训练中,需要判断至今为之发生了什么,过去输入的所有数据都对当下的分类造成影响
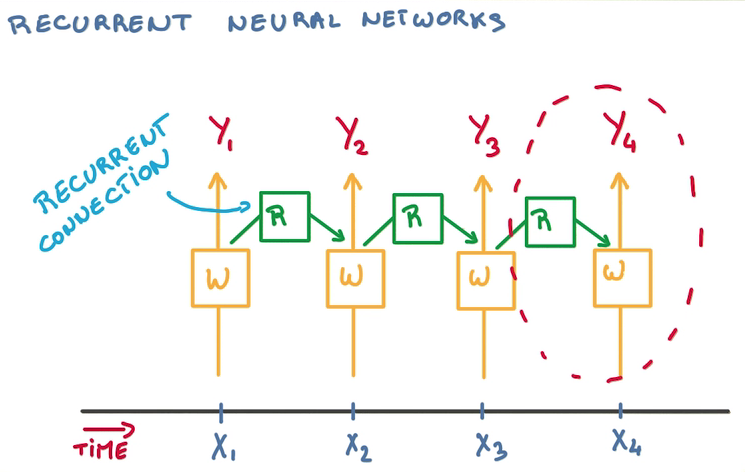
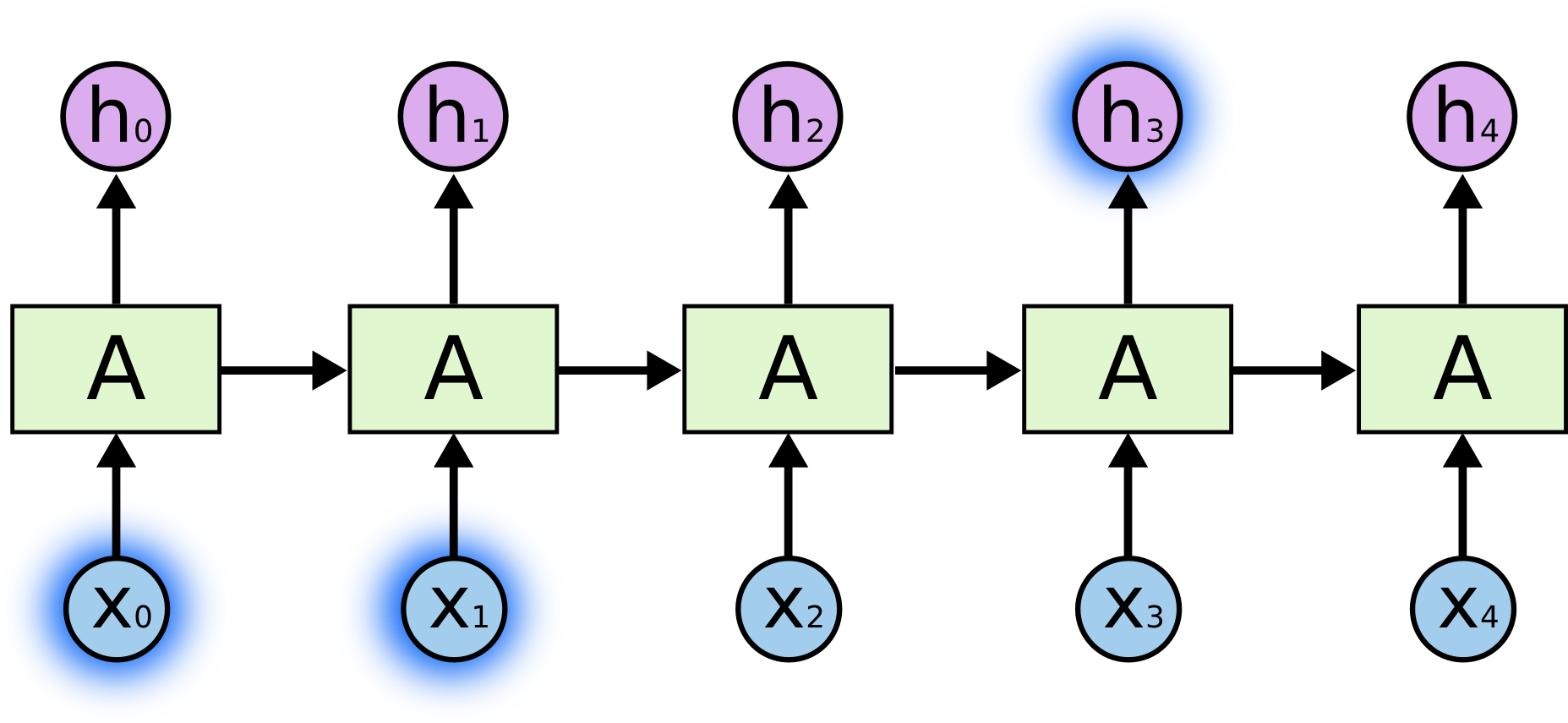
RNNs的目的使用来处理序列数据。RNNs之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关。具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNNs能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关,下图便是一个典型的RNNs:
RNNs包含输入单元(Input units),输入集标记为{x0,x1,…,xt,xt+1,…},而输出单元(Output units)的输出集则被标记为{y0,y1,…,yt,yt+1.,..}。RNNs还包含隐藏单元(Hidden units),我们将其输出集标记为{s0,s1,…,st,st+1,…},这些隐藏单元完成了最为主要的工作。你会发现,在图中:有一条单向流动的信息流是从输入单元到达隐藏单元的,与此同时另一条单向流动的信息流从隐藏单元到达输出单元。在某些情况下,RNNs会打破后者的限制,引导信息从输出单元返回隐藏单元,这些被称为“Back Projections”,并且隐藏层的输入还包括上一隐藏层的状态,即隐藏层内的节点可以自连也可以互连。
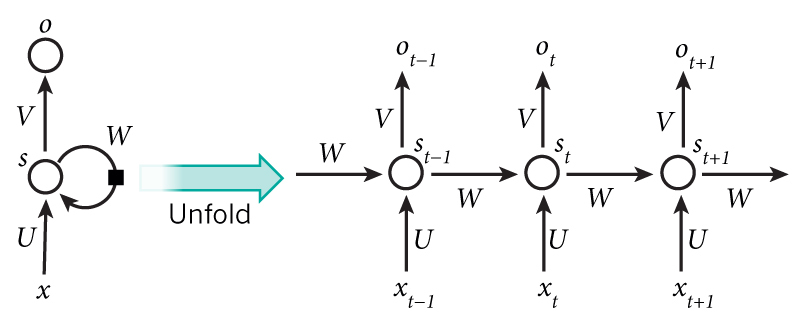
上图将循环神经网络进行展开成一个全神经网络。例如,对一个包含5个单词的语句,那么展开的网络便是一个五层的神经网络,每一层代表一个单词。对于该网络的计算过程如下:
xt表示第t,t=1,2,3…步(step)的输入。比如,x1为第二个词的one-hot向量(根据上图,x0为第一个词); PS:使用计算机对自然语言进行处理,便需要将自然语言处理成为机器能够识别的符号,加上在机器学习过程中,需要将其进行数值化。而词是自然语言理解与处理的基础,因此需要对词进行数值化,词向量(Word Representation,Word embeding)[1]便是一种可行又有效的方法。何为词向量,即使用一个指定长度的实数向量v来表示一个词。有一种种最简单的表示方法,就是使用One-hot vector表示单词,即根据单词的数量|V|生成一个|V| * 1的向量,当某一位为一的时候其他位都为零,然后这个向量就代表一个单词。缺点也很明显:
st为隐藏层的第t步的状态,它是网络的记忆单元。 st根据当前输入层的输出与上一步隐藏层的状态进行计算。st=f(Uxt+Wst−1),其中f一般是非线性的激活函数,如tanh或ReLU,在计算s0时,即第一个单词的隐藏层状态,需要用到s−1,但是其并不存在,在实现中一般置为0向量;
ot是第t步的输出,如下个单词的向量表示,ot=softmax(Vst).
需要注意的是:
你可以认为隐藏层状态st是网络的记忆单元. st包含了前面所有步的隐藏层状态。而输出层的输出ot只与当前步的st有关,在实践中,为了降低网络的复杂度,往往st只包含前面若干步而不是所有步的隐藏层状态;
在传统神经网络中,每一班个网络层的参数是不共享的。而在RNNs中,每输入一步,每一层各自都共享参数U,V,W。其反映着RNNs中的每一步都在做相同的事,只是输入不同,因此大大地降低了网络中需要学习的参数;这里并没有说清楚,解释一下,传统神经网络的参数是不共享的,并不是表示对于每个输入有不同的参数,而是将RNN是进行展开,这样变成了多层的网络,如果这是一个多层的传统神经网络,那么xt到st之间的U矩阵与xt+1到st+1之间的U是不同的,而RNNs中的却是一样的,同理对于s与s层之间的W、s层与o层之间的V也是一样的。
上图中每一步都会有输出,但是每一步都要有输出并不是必须的。比如,我们需要预测一条语句所表达的情绪,我们仅仅需要关系最后一个单词输入后的输出,而不需要知道每个单词输入后的输出。同理,每步都需要输入也不是必须的。RNNs的关键之处在于隐藏层,隐藏层能够捕捉序列的信息。
用通俗的例子解释:
演奏音乐时,乐器将力转成相应的震动产生声音,而整个演奏拥有一个主旋律贯穿全曲。其中乐器的物理特性就相当于参数,同一乐器在各个时刻物理特性在各个时刻都是共享的。其内在也有一个隐藏的主旋律基准(主题),旋律信息(上一个状态乘与主题)与音乐信息(输入称与参数)共同决定下一时刻的实际声音。
或者是:捏陶瓷:不同角度相当于不同的时刻

若用前馈网络:网络训练过程相当于不用转盘,而是徒手将各个角度捏成想要的形状。不仅工作量大,效果也难以保证。
若用递归网络:网络训练过程相当于在不断旋转的转盘上,以一种手势捏造所有角度。工作量降低,效果也可保证。
而对于RNN,我的理解就是对于一个句子或者文本,那个参数可以看成是语法结构或者一般规律,而下一个单词的预测必须是上一个单词和一般规律或者语法结构向结合的。我们知道,语法结构和一般规律在语言当中是共享的,所以,参数自然就是共享的!
rnn的训练
对于RNN是的训练和对传统的ANN训练一样。同样使用BP误差反向传播算法,不过有一点区别。如果将RNNs进行网络展开,那么参数W,U,V是共享的,而传统神经网络却不是的。并且在使用梯度下降算法中,每一步的输出不仅依赖当前步的网络,并且还以来前面若干步网络的状态。比如,在t=4时,我们还需要向后传递三步,以及后面的三步都需要加上各种的梯度。该学习算法称为Backpropagation Through Time (BPTT)。后面会对BPTT进行详细的介绍。需要意识到的是,在vanilla RNNs训练中,BPTT无法解决长时依赖问题(即当前的输出与前面很长的一段序列有关,一般超过十步就无能为力了),因为BPTT会带来所谓的梯度消失或梯度爆炸问题(the vanishing/exploding gradient problem)。当然,有很多方法去解决这个问题,如LSTMs便是专门应对这种问题的。
注意在语言模型(RNNLM)中,若输入的序列的是A,B,C,D那么训练的label序列就是B,C,D,D,然后在此基础上进行反向传播
或者简单的理解:
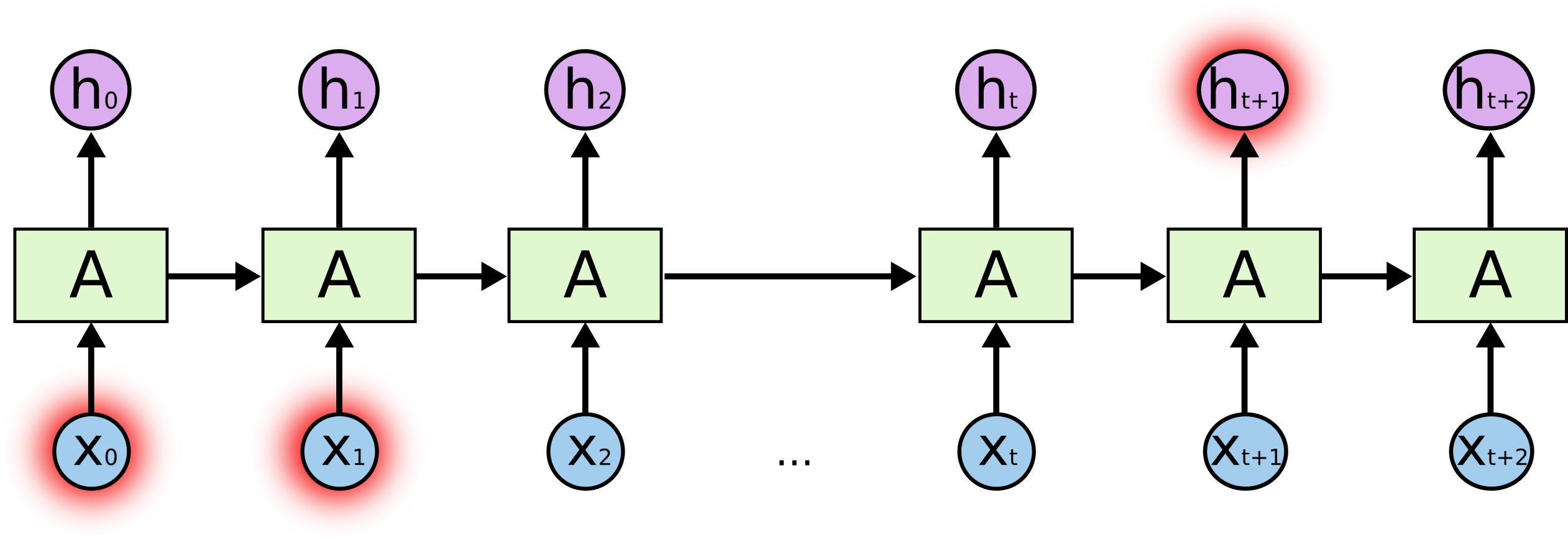
在上面的图中,一大块神经网络,A,观察一些输入xt,输出一个值ht。循环允许信息从网络的一步传到下一步。
这些循环使得循环神经网络似乎有点神秘。然而,如果你想多一点,其实它们跟一个正常的神经网络没有神秘区别。一个循环神经网络可以被认为是同一个网络的多重副本,每个部分会向继任者传递一个信息。想一想,如果我们展开了循环会发生什么:
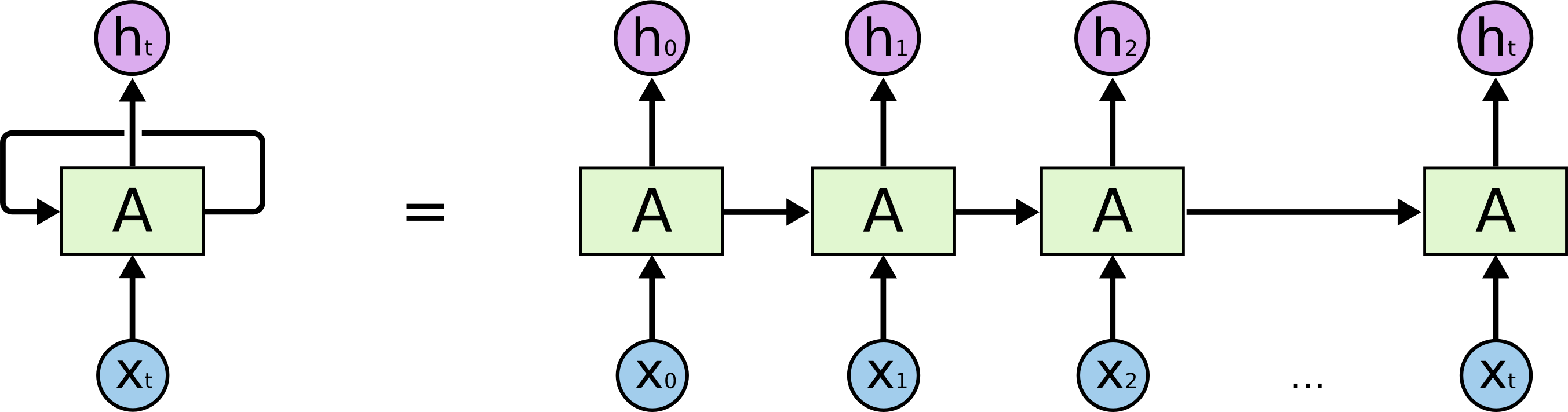
这个链式本质揭示了,循环神经网络跟序列和列表是紧密相关的。它们是神经网络为这类数据而生的自然架构
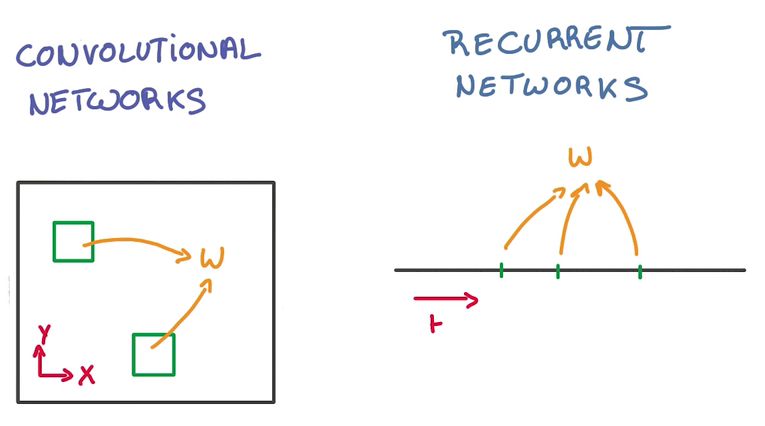
我们需要记住的是,深度是怎么减少参数的,很大原因就是参数共享,而CNN是 在空间上共享参数,RNN是在时间上(顺序上)共享参数:
有时候,我们只需要查看最近的信息来执行现在的任务,例如,考虑一个语言模型试图基于先前的词预测下一个词。如果我们要预测“the clouds are in the sky”,我们不需要其他更遥远的上下文 —— 非常明显,下一个词就应该是sky。在这样的例子中,相关信息和目的地之间的距离是很小的。RNN可以学着区使用过去的信息。
但也有一些情况是我们需要更多上下文的。考虑预测这个句子中最后一个词:“I grew up in France… I speak fluent French.” 最近的信息表明下一个词可能是一种语言的名字,但如果我们想要找出是哪种语言,我们需要从更久远的地方获取France的上下文。相关信息和目标之间的距离完全可能是非常巨大的。
不幸的是,随着距离的增大,RNN变得不能够连接信息。
长期依赖导致的神经网络困境
理论上,RNN是绝对能够处理这样的“长期依赖的”。人类可以仔细地从这些词中找到参数然后解决这种形式的一些雏形问题。然而,实践中,RNN似乎不能够学习到这些。 Hochreiter (1991) [German] 和 Bengio, et al. 1994年曾探索过这个问题,他们发现了一些非常根本的导致RNN难以生效的原因。
万幸的是,LSTM没有这个问题!也就是说不会产生由于太多层导致的梯度爆炸或者梯度消亡的问题!
LSTM的关键在于cell的状态,也就是图中贯穿顶部的那条水平线。
cell的状态像是一条传送带,它贯穿整条链,其中只发生一些小的线性作用。信息流过这条线而不改变是非常容易的。
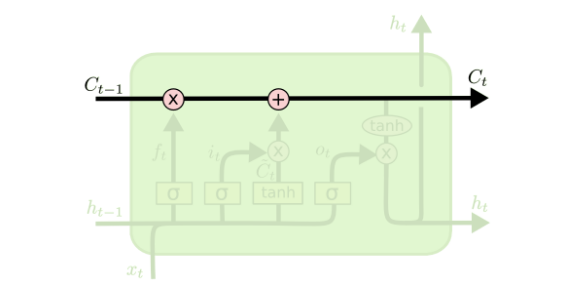
LSTM确实有能力移除或增加信息到cell状态中,由被称为门的结构精细控制。
门是一种让信息可选地通过的方法。它们由一个sigmoid神经网络层和一个点乘操作组成。
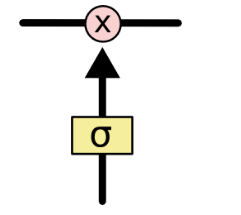
sigmod层输出[0, 1]区间内的数,描述了每个部分中应该通过的比例。输出0意味着“什么都不能通过”,而输出1意味着“让所有东西通过!”。
一个LSTM有四个这样的门,以保护和控制cell的状态。
我们的LSTM的第一步是决定我们需要从cell状态中扔掉什么样的信息。这个决策由一个称为“遗忘门”的sigmoid层做出。它观察h(t-1)和x(t),位cell状态Ct-1中每个number输出一个0和1之间的数。1代表“完全保留这个值”,而0代表“完全扔掉这个值”。
让我们回到我们那个基于上文预测最后一个词的语言模型。在这样一个问题中,cell的状态可能包含当前主题的种类,这样才能使用正确的名词。当我们看到一个新的主题的时候,我们会想要遗忘旧的主题的种类。
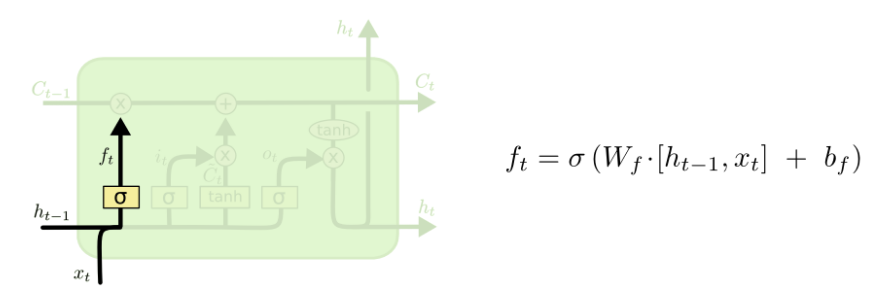
第二步是决定我们需要在cell state里存储什么样的信息。这个问题有两个部分。第一,一个sigmoid层调用“输入门”以决定哪些数据是需要更新的。然后,一个tanh层为新的候选值创建一个向量C~t,这些值能够加入state中。下一步,我们要将这两个部分合并以创建对state的更新。
在我们的语言模型的例子中,我们想要把主题的种类加入到cell state中,以替代我们要遗忘的旧的种类。
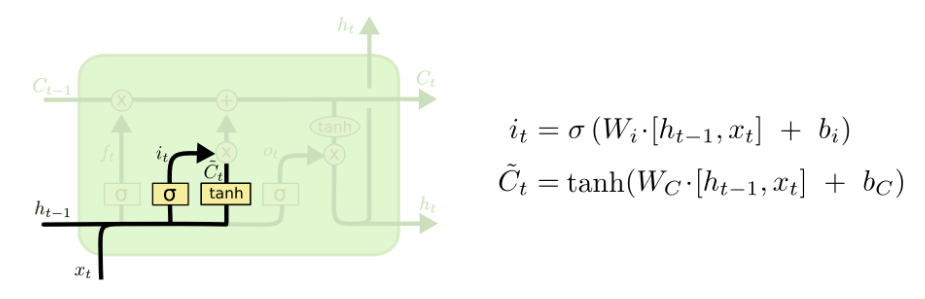
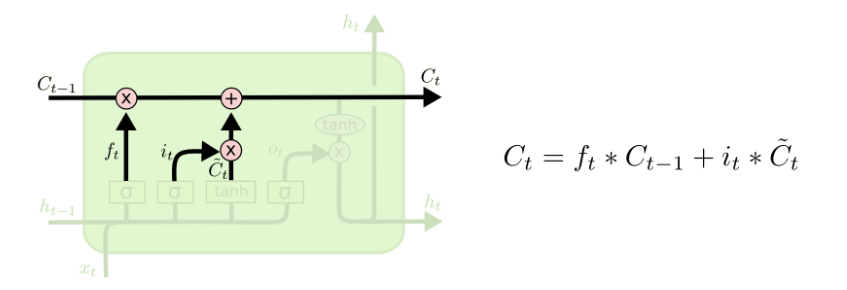
现在是时候更新旧的cell stateCt-1到新的cell stateCt。前一步已经决定了我们需要做的事情,我们只需要实现它。
我们把旧的state与ft相乘,遗忘我们先前决定遗忘的东西,然后我们加上it * C`(t)。这是新的候选值,受我们对每个状态值的更新度约束而缩放。
在语言模型的例子中,这就是我们真正扔掉旧主题种类,并增加新的信息的地方,正如我们之前所决定的。
最后,我们需要决定要输出的东西。这个输出基于我们的cell state,但会是一个过滤版本。首先,我们运行一个sigmoid层,以决定cell state中的那个部分是我们将要输出的。然后我们把cell state放进tanh(将数值压到-1和1之间),最后将它与sigmoid门的输出相乘,这样我们就只输出了我们想要的部分了。
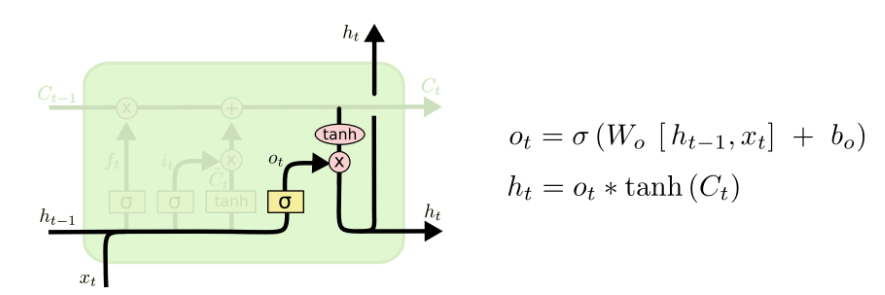
语言模型的例子中,由于它仅关注一个主题,它可能会输出与一个动词相关的信息,以防后面还有其他的词。比如,它可能输出这个主题是单数还是复数,让我们知道如果后面还有东西,动词才会对应出现。
到目前为止,我们所讲述的只是很普通的lstm,其实它有非常非常多的变种,详情了解可以看下这篇cs224d的学习笔记
关于lstm有这样一篇博客讲的很好:地址
对应的中文版中文版
LSTM只能避免RNN的梯度消失(gradient vanishing);梯度膨胀(gradient explosion)不是个严重的问题,一般靠裁剪后的优化算法即可解决,比如gradient clipping(如果梯度的范数大于某个给定值,将梯度同比收缩),下面简单说说LSTM如何避免梯度消失

有了上面的模型之后,我们可以根据上文来推测下文,甚至创造下文,预测,筛选最大概率的词,喂回,继续预测……
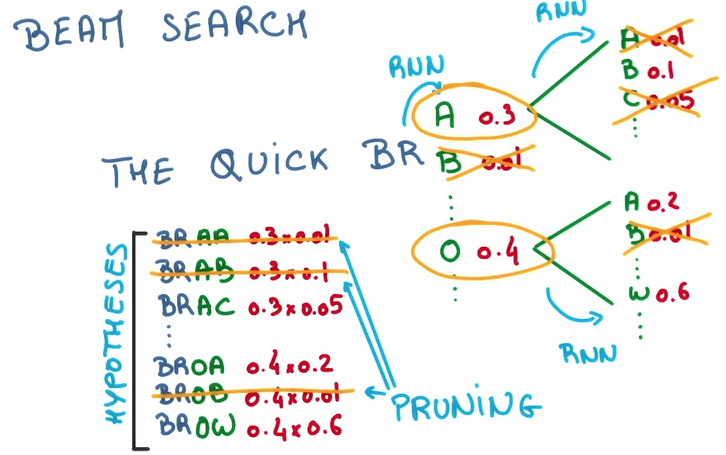
RNN将variable length sequence问题变成了fixed length vector问题,同时因为实际上我们能利用vector进行预测,我们也可以将vector变成sequence


