

欢迎在文章下方评论,建议用电脑看
因为rnn和lstm的讲解在这篇博文已经讲过比较多了,这里就不详细讲解rnn和lstm了,下面主要是rnn的训练和一种变种!
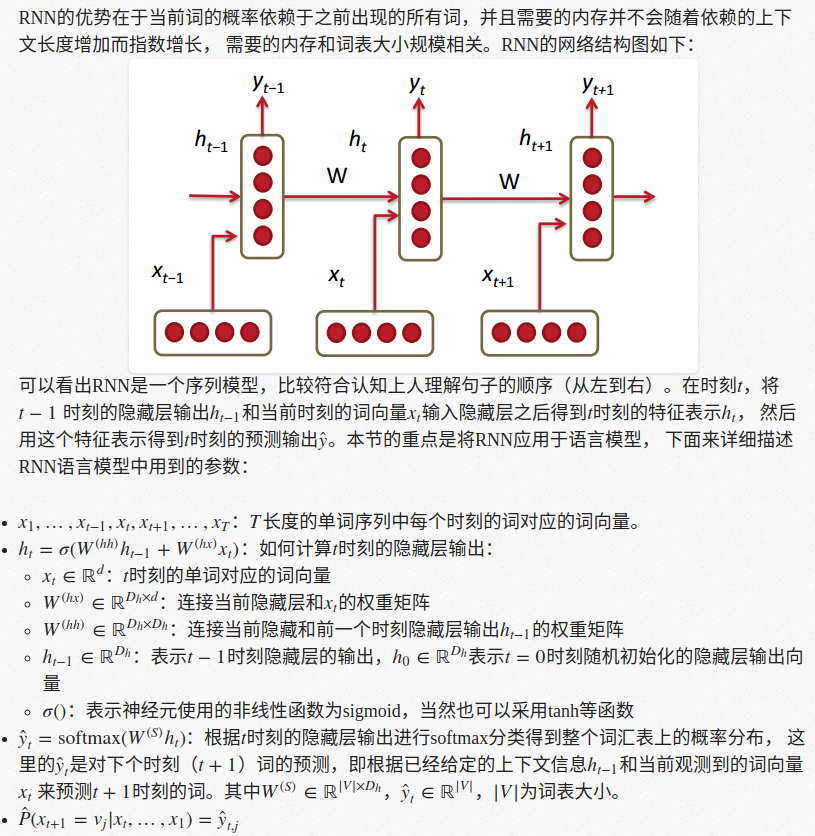
RNN语言模型中非常关键的一点是每个时刻采用的W矩阵都是一个,所以参数规模不会随着依赖上下文的长度增加而指数增长。 通常来说采用交叉熵作为损失函数,那么在t时刻的损失为:
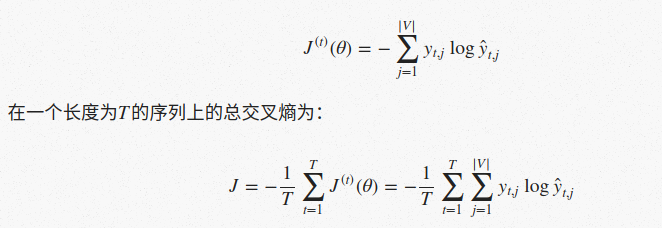
用来衡量语言模型的一个常用指标是困惑度(perplexity),困惑度越低表示预测下个词的置信度越高,困惑度和交叉熵的关系如下:
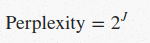
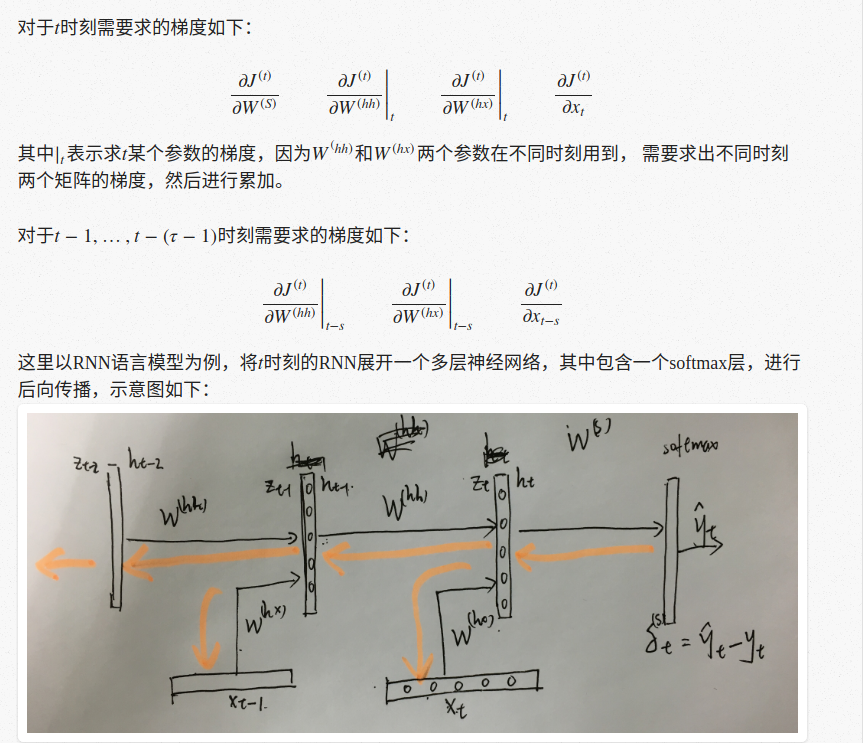
其实RNN本质上还是一个普通的多层神经网络,只是层与层之间使用的是同一个权重矩阵而已, 同样可以利用后向误差传播的原理来进行后向误差传播, 只需要把t时刻的误差一直传播到t=0时刻,但是在实际实现的时候一般只需要向后传播τ≈3−5个时间单位。

笔记原文:
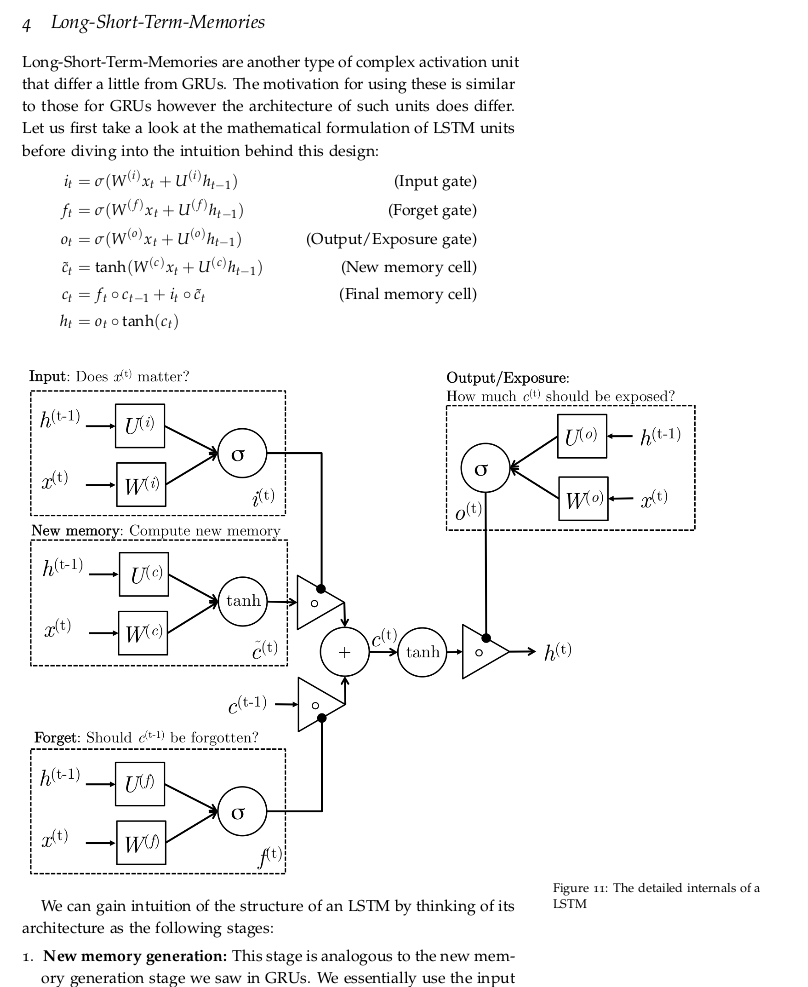

GRU可以看成是LSTM的变种,GRU把LSTM中的forget gate和input gate用update gate来替代。 把cell state和隐状态h(t)进行合并,在计算当前时刻新信息的方法和LSTM有所不同。
笔记原文:


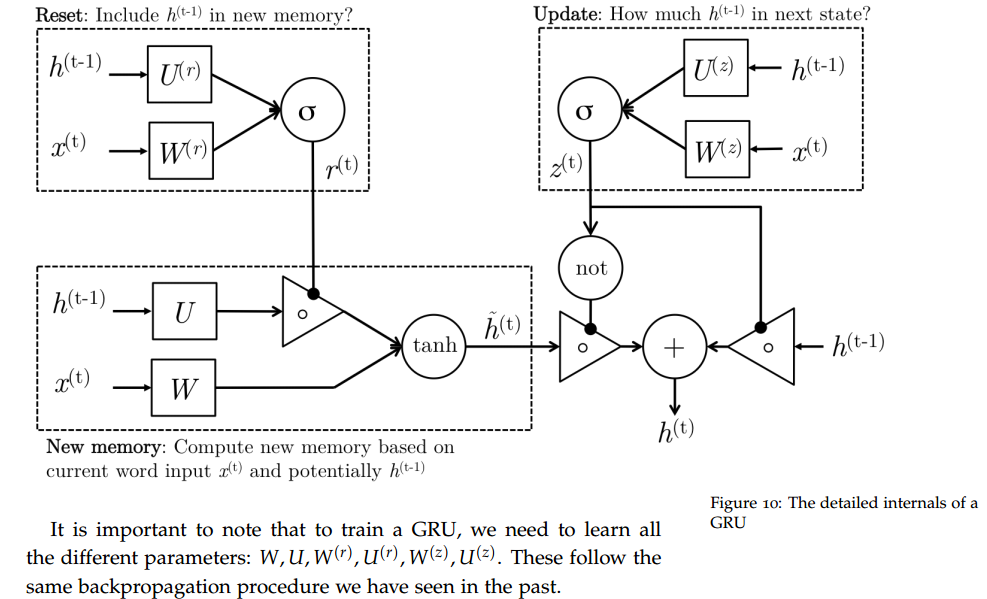
下图是GRU更新h(t)的过程:
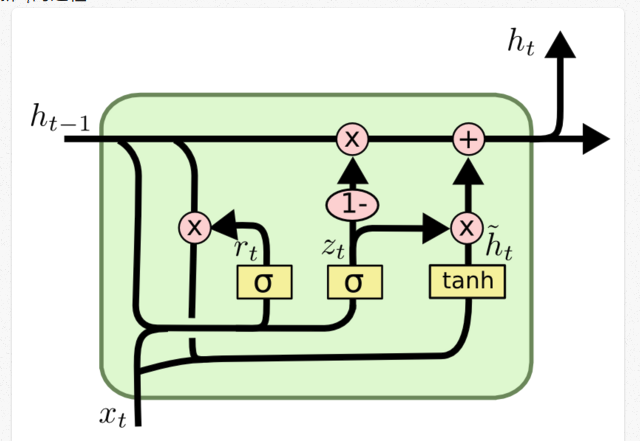

GRU有两个门,LSTM有三个门;GRU没有不同于隐状态的内部记忆c_{t},没有LSTM中的输出门;GRU输入门和遗忘门通过更新门z进行耦合,重置门r被直接应用于之前的隐状态。因此,LSTM中的重置门的责任实质上被分割到了r和z中。GRU在计算输出时,没有使用第二个非线性单元。
现在你已经看到了两个能够解决消失梯度问题的模型,你可能会疑惑:使用哪一个?GRU非常新,它们之间的权衡没有得到完全的研究。根据Empirical Evaluation of Gated Recurrent Neural Networks on Sequence Modeling和 An Empirical Exploration of Recurrent Network Architectures的实验结果,两者之前没有很大差别。在许多任务中,两种结构产生了差不多的性能,调整像层大小这样的参数可能比选择合适的架构更重要。GRU的参数更少,因而训练稍快或需要更少的数据来泛化。另一方面,如果你有足够的数据,LSTM的强大表达能力可能会产生更好的结果。
两宴书长,一与家天斜。出寒看阶帆,竺却参雴飞。


