

欢迎在文章下方评论,建议用电脑看
为什么要用词向量:
自然语言处理系统通常将词汇作为离散的单一符号,例如 “cat” 一词或可表示为 Id537 ,而 “dog” 一词或可表示为 Id143。这些符号编码毫无规律,无法提供不同词汇之间可能存在的关联信息。换句话说,在处理关于 “dogs” 一词的信息时,模型将无法利用已知的关于 “cats” 的信息(例如,它们都是动物,有四条腿,可作为宠物等等)。可见,将词汇表达为上述的独立离散符号将进一步导致数据稀疏,使我们在训练统计模型时不得不寻求更多的数据。而词汇的向量表示将克服上述的难题。
word embedding的意思是:给出一个文档,文档就是一个单词序列比如 “A B A C B F G”, 希望对文档中每个不同的单词都得到一个对应的向量(往往是低维向量)表示。比如,对于这样的“A B A C B F G”的一个序列,也许我们最后能得到:A对应的向量为[0.1 0.6 -0.5],B对应的向量为[-0.2 0.9 0.7] (此处的数值只用于示意)
之所以希望把每个单词变成一个向量,目的还是为了方便计算,比如“求单词A的同义词”,就可以通过“求与单词A在cos距离下最相似的向量”来做到。
需要注意的是和下面要讲的word2vec的联系和区别,word embedding 是一个将词向量化的概念,为区别one-hot的词向量,可翻译成词嵌入。而word2vec是谷歌提出一种word embedding 的工具或者算法集合
向量空间模型 (VSMs)将词汇表达(嵌套)于一个连续的向量空间中,语义近似的词汇被映射为相邻的数据点。向量空间模型在自然语言处理领域中有着漫长且丰富的历史,不过几乎所有利用这一模型的方法都依赖于 分布式假设,其核心思想为出现于上下文情景中的词汇都有相类似的语义。采用这一假设的研究方法大致分为以下两类:基于计数的方法 (e.g. 潜在语义分析, Glove), 和 预测方法 (e.g. 神经概率化语言模型,word2vec).关于这个可以看下一篇关于word vectors的cs224d笔记
简而言之:基于计数的方法计算某词汇与其邻近词汇在一个大型语料库中共同出现的频率及其他统计量,然后将这些统计量映射到一个小型且稠密的向量中。预测方法则试图直接从某词汇的邻近词汇对其进行预测,在此过程中利用已经学习到的小型且稠密的嵌套向量。
在这里,我们主要讨论的是神经概率化语言模型
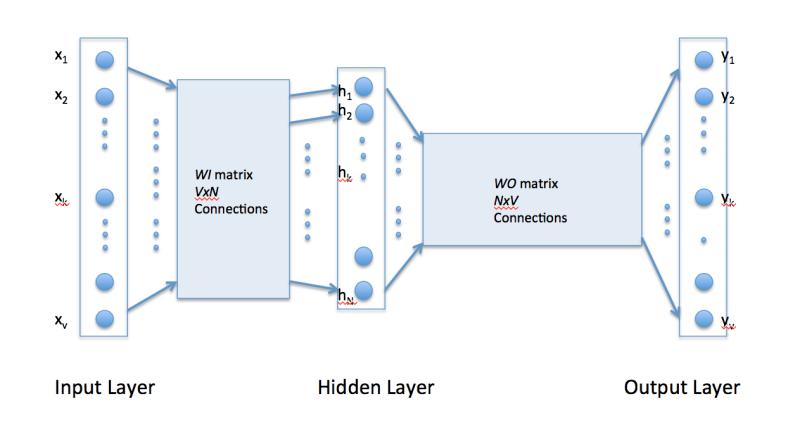

下面看图说下整体步骤是怎么样的:
好了,到了举例子时间:
如果我们的语料仅仅有这3句话: “the dog saw a cat”, “the dog chased the cat”, “the cat climbed a tree”. 那么单词字典只有8个单词: “the”, “dog”, “saw”, “a”, “cat”, “chased”, “climbed”, “tree”.
那么V=8, 输入层的初始就可以是:
[1, 1, 1, 1, 1, 1, 1, 1] 代表: [“the”, “dog”, “saw”, “a”, “cat”, “chased”, “climbed”, “tree”]
输入[“”, “dog“, “”, “”, “”, “”, “”, “”] 可以表示为: [0, 1, 0, 0, 0, 0, 0, 0]
输入[“”, “”, “saw“, “” , “”, “”, “”, “”] 可以表示为: [0, 0, 1, 0, 0, 0, 0,0]
如果是在字典中有的, 就用1表示
W0 的大小是NxV, 于是, 通过训练完毕的WI 和W0 , 只要输入单词, 就能预测出最符合这个上下文的下一个单词. 当然这个单词一定是字典中有的, 就是说在大小V中的字典中, 选出概率最大的那个单词.
但需要注意的是:Word2vec是一种可以进行高效率词嵌套学习的预测模型。其有两种变体是现在比较常用的,分别为:连续词袋模型(CBOW)及Skip-Gram模型。从算法角度看,这两种方法非常相似,其区别为CBOW根据源词上下文词汇(’the cat sits on the’)来预测目标词汇(例如,‘mat’),而Skip-Gram模型做法相反,它通过目标词汇来预测源词汇。Skip-Gram模型采取CBOW的逆过程的动机在于:CBOW算法对于很多分布式信息进行了平滑处理(例如将一整段上下文信息视为一个单一观察量)。很多情况下,对于小型的数据集,这一处理是有帮助的。相形之下,Skip-Gram模型将每个“上下文-目标词汇”的组合视为一个新观察量,这种做法在大型数据集中会更为有效。
词表中每个词的词向量都存在一个矩阵中。由于存在两套词向量,因此就有两个矩阵:输入词矩阵nV的矩阵,其每一列都是一个词作为周围词时的词向量;输出词是一个vn的矩阵,其每一行都是一个词作为中心词时的词向量。比如说若想取出词作为周围词时的词向量,只要知道词在词表中的编号即可,取出的操作相当于用输入词矩阵乘以词的one-hot representation。
也就是说,每个词有两个向量,在最后在平均或其他操作组合成一个向量
讲完这些,下面来讲讲Word2vec的两个变体模型,先讲不加速的,然后再讲其加速改进!
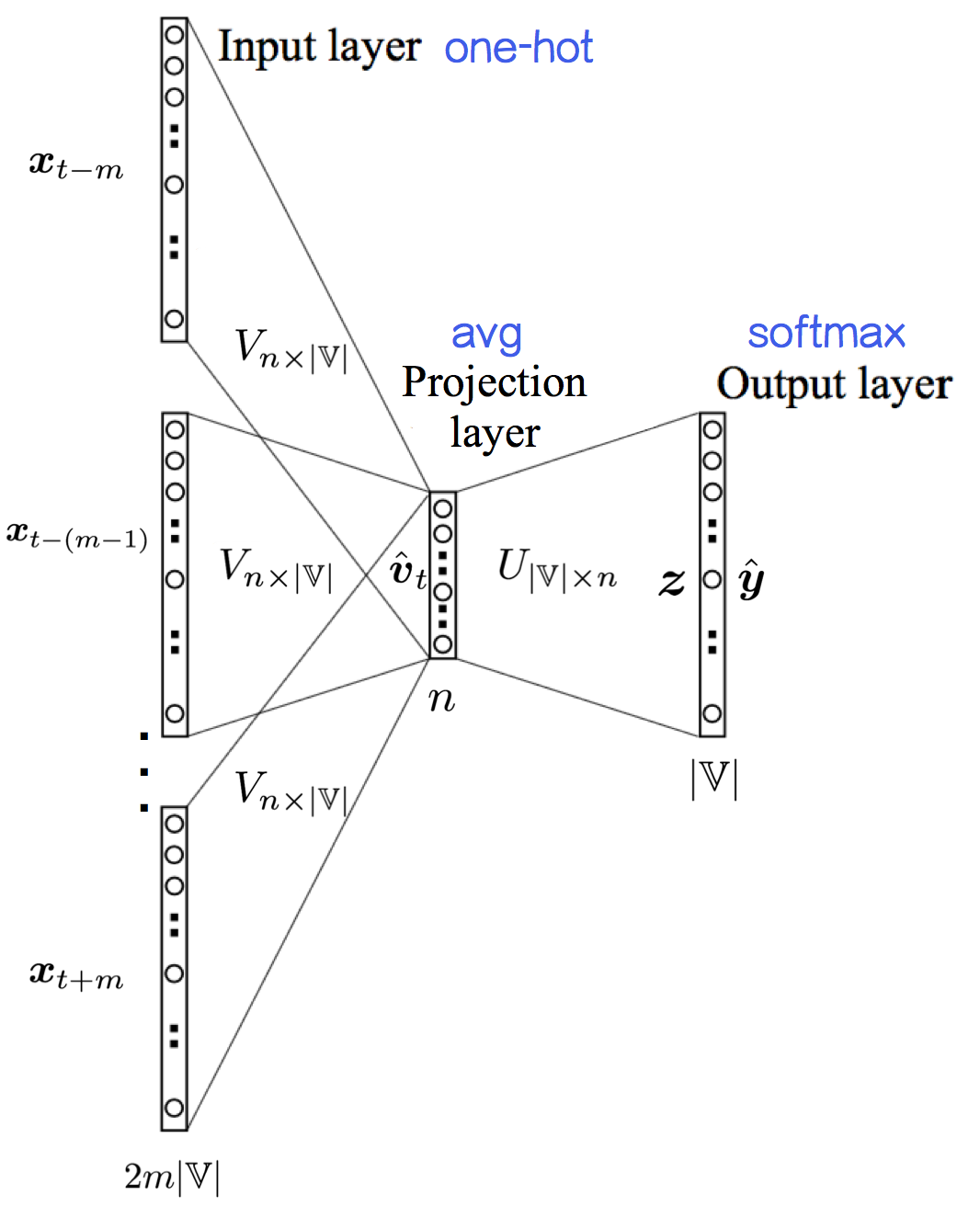
不带加速的CBOW模型是一个两层结构,通过上下文来预测中心词——
| 输入层:n 个节点,上下文共 2m 个词的词向量的平均值,其中,这里的n表示词向量的维数, | V | 表示词典的基数 |
| 输入层到输出层的连接边:输出词矩阵 U | V | ×n ; |
| 输出层: | V | 个节点。第 i 个节点代表中心词是词 wi_ 的概率。 |
如果要“看做”三层结构的话,可以认为——
| 输入层:2m× | V | 个节点,上下文共 2m 个词的one-hot representation |
| 输入层到投影层到连接边:输入词矩阵 Vn× | V | ; |
投影层:n 个节点,上下文共 2m 个词的词向量的平均值;
| 投影层到输出层的连接边:输出词矩阵 U | V | ×n ; |
| 输出层: | V | 个节点。第 i 个节点代表中心词是词 wi_ 的概率。 |
这样表述相对清楚,将one-hot到word embedding那一步描述了出来。
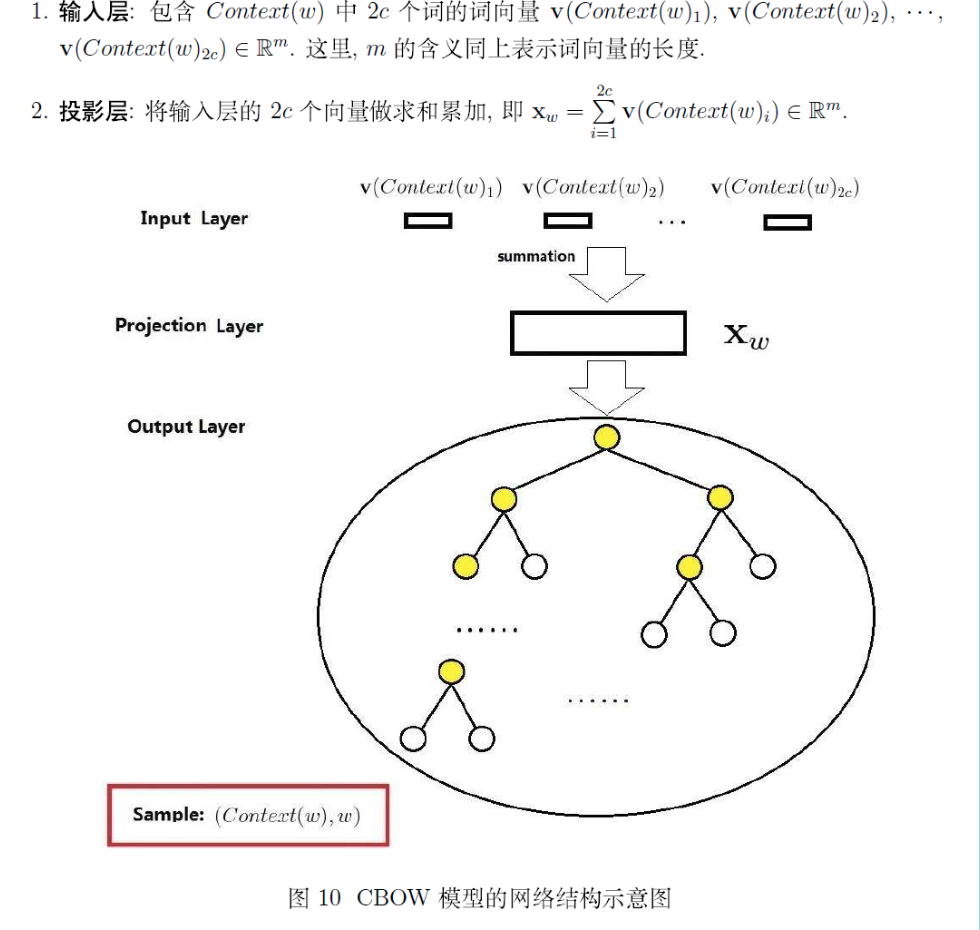
其实这些词向量就是神经网络里的参数,生成词向量的过程就是一个参数更新的过程。那么究竟是什么参数呢?就是这个网络的第一层和第二层:将one-hot向量转换成低维词向量的这一层(虽然大家都不称之为一层,但在我看来就是一层),因为word2vec的输入是one-hot。one-hot可看成是1*N(N是词总数)的矩阵,与这个系数矩阵(N*M, M是word2vec词向量维数)相乘之后就可以得到1*M的向量,这个向量就是这个词对应的词向量了。那么对于那个N*M的矩阵,每一行就对应了每个单词的词向量。接下来就是进入神经网络,然后通过训练不断更新这个矩阵。注意这里得到两个词向量,之后还要把两个词向量变成一个。关于这个还可以查看这篇博文

以词表中的全部词作为叶子节点,词频作为节点的权,构建Huffman树,作为输出。Huffman树是二叉树,在叶子节点及叶子节点的权给定的情况下,该树的带权路径长度最短(一个节点的带权路径长度指根节点到该节点的路径长度乘以该节点的权,树的带权路径长度指全部叶子节点的带权路径长度之和)。直观上可以看出,叶子节点的权越大,则该叶子节点就应该离根节点越近。因此对于模型来说就是,词频越高的词,距离根节点就越近。
关于Hierarchical Softmax详细可以查看这篇博文
现在用到比较多的是这种策略
第二种加速策略是Negative Sampling(NEG,负采样),这是Noise-Contrastive Estimation(NCE,噪声对比估计)的简化版本:把语料中的一个词串的中心词替换为别的词,构造语料 𝔻D 中不存在的词串作为负样本。因此在这种策略下,优化目标变为了:最大化正样本的概率,同时最小化负样本的概率。对于一个词串 (w,c)(w,c) ( cc 表示 ww 的上下文),用二项Logistic回归模型对其是正样本的概率建模:

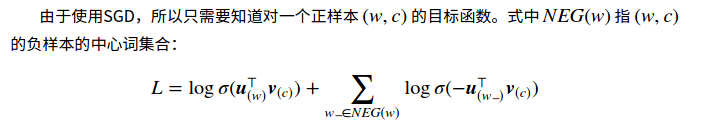
下面就第二种加速举个例子:



参考资料:
《深度学习》-Bengio
《统计学习方法》-李航
《机器学习》-周志华
《机器学习实战》-Peter Harrington
斯坦福大学公开课-机器学习
网上的各位大牛的博文


