

欢迎在文章下方评论,建议用电脑看
大概的DQN算法,在之前的笔记中有提及,请查看这篇文章
NIPS DQN在基本的Deep Q-Learning算法的基础上使用了Experience Replay经验池。通过将训练得到的数据储存起来然后随机采样的方法降低了数据样本的相关性。提升了性能。接下来,Nature DQN做了一个改进,就是增加Target Q网络。也就是我们在计算目标Q值时使用专门的一个目标Q网络来计算,而不是直接使用预更新的Q网络。这样做的目的是为了减少目标计算与当前值的相关性。
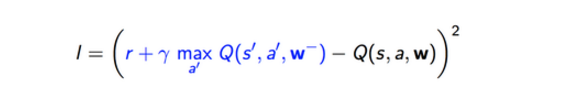
如上面的损失函数公式所示,计算目标Q值的网络使用的参数是w-,而不是w。就是说,原来NIPS版本的DQN目标Q网络是动态变化的,跟着Q网络的更新而变化,这样不利于计算目标Q值,导致目标Q值和当前的Q值相关性较大。因此提出单独使用一个目标Q网络。那么目标Q网络的参数如何来呢?还是从Q网络中来,只不过是延迟更新。也就是每次等训练了一段时间再将当前Q网络的参数值复制给目标Q网络。
神经网络的更新过程是这样的:两个网络,首先输入的都是状态,输出的都是Q值,然后选择k次动作(这里是贪婪或者是随机选择的,一般设为90%的选择最优,然后10%的随机选取。),在之后进行更新参数。loss就是计算目标(现实)Q值和估计Q值之间的差距,来更新Q估计网络。
在Nature DQN出来之后,肯定很多人在思考如何改进它。那么DQN有什么问题呢?
下面列出一些坑:
目标Q值的计算准确吗?全部通过max Q来计算有没有问题?
随机采样的方法好吗?按道理不同样本的重要性是不一样的
Q值代表状态,动作的价值,那么单独动作价值的评估会不会更准确?
DQN中使用\epsilon-greedy的方法来探索状态空间,有没有更好的做法?
使用卷积神经网络的结构是否有局限?加入RNN呢?
DQN无法解决一些高难度的Atari游戏比如Montezuma’s Revenge,如何处理这些游戏?
DQN训练时间太慢了,跑一个游戏要好几天,有没有办法更快?
DQN训练是单独的,也就是一个游戏弄一个网络进行训练,有没有办法弄一个网络同时掌握多个游戏,或者训练某一个游戏后将知识迁移到新的游戏?
DQN能否用在连续动作输出问题?
除了上面的问题,其他的就是将DQN应用到其他领域比如文字理解,目标定位等等,也就是DQN的拓展研究,这里就不罗列相关文章了。上面的这些成果基本出自DeepMind之手,只有一两篇出自其他大牛,比如Pieter Abbeel,Ruslan Salakhutdinov。
大幅度提升DQN玩Atari性能的主要就是Double DQN,Prioritised Replay还有Dueling Network三大方法。
David Silver在ICML 2016中的Tutorial上做了介绍:深度增强学习Tutorial 下图引用其PPT:

简单说明一下:
Double DQN:目的是减少因为max Q值计算带来的计算偏差,或者称为过度估计(over estimation)问题,用当前的Q网络来选择动作,用目标Q网络来计算目标Q。
Prioritised replay:也就是优先经验的意思。优先级采用目标Q值与当前Q值的差值来表示。优先级高,那么采样的概率就高。
Dueling Network:将Q网络分成两个通道,一个输出V,一个输出A,最后再合起来得到Q。如下图所示(引用自Dueling Network论文)。这个方法主要是idea很简单但是很难想到,然后效果一级棒,因此也成为了ICML的best paper。


