

欢迎在文章下方评论,建议用电脑看
因为神经网络基础已经讲过了,在这里就不重复细讲,在这里主要讲的是结合nlp中的一些trick和tip,顺带讲下对交叉熵的进一步理解
下面讲述的是怎么才能训练出比较好的神经网络,一些tip&trick

还有就是在检查神经网络的时候的梯度检查:



文中简单介绍了一下rnn和他为什么难以训练,下面给出课件:



文中也给出,因为我们知道训练rnn很容易梯度消失或者梯度爆炸,下面是一种切割梯度的方式,来阻止梯度爆炸:

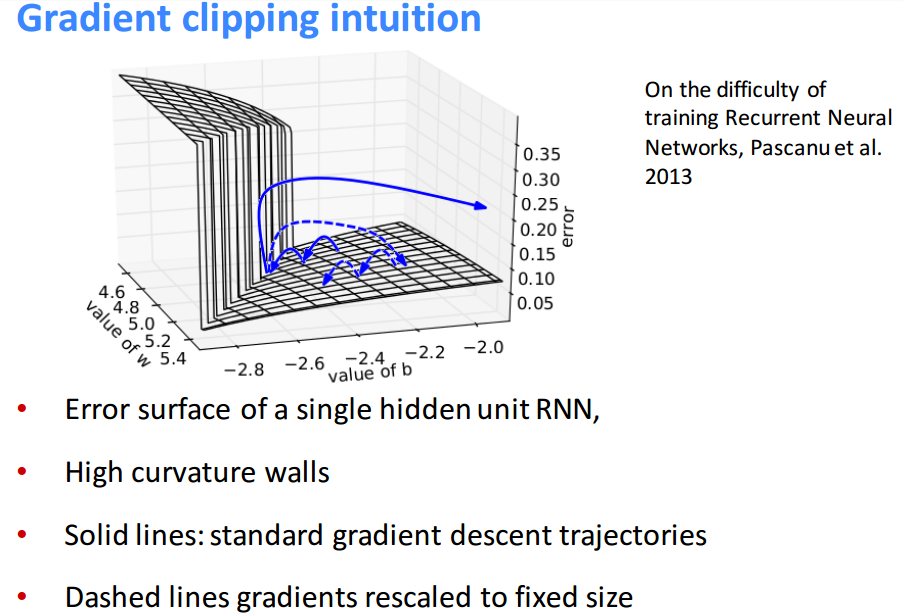
需要注意的是,在后面讲到的lstm中,它是可以防止梯度消失,但不能防止梯度爆炸,具体原因请查看这篇博文


这里很明白的说明了最小化交叉熵就是在最小化kl散度,好的,一开始并不知道它是什么,下面摘自网上,对于kl散度和交叉熵的解释:

比如TD-IDF算法就可以理解为相对熵的应用:词频在整个语料库的分布与词频在具体文档中分布之间的差异性。交叉熵可在神经网络(机器学习)中作为损失函数,p表示真实标记的分布,q则为训练后的模型的预测标记分布,交叉熵损失函数可以衡量p与q的相似性。交叉熵作为损失函数还有一个好处是使用sigmoid函数在梯度下降时能避免均方误差损失函数学习速率降低的问题,因为学习速率可以被输出的误差所控制。
PS:
通常“相对熵”也可称为“交叉熵”,因为真实分布p是固定的,D(p||q)由H(p,q)决定。当然也有特殊情况,彼时2者须区别对待。
尽管KL散度从直观上是个度量或距离函数,但它并不是一个真正的度量或者距离,因为它不具有对称性,即D(p||q)!=D(q||p)


