欢迎在文章下方评论,建议用电脑看
下面是有关GloVe模型的描述:

下面是关于word2vec和Glove两个模型的区别,文章摘自quora

简单说明,在我看在word2vec就是一个预测模型,然后是可能根据上下文来预测中心词或者反过来,而Glove是说明一个词袋的词的关系,是一个Count-based models一开始是高维的,然后提取其中的主要因子,然后用低维来表示高维中绝大部分的信息。 还有就是 The additional benefits of GloVe over word2vec is that it is easier to parallelize the implementation which means it’s easier to train over more data, which, with these models, is always A Good Thing.,这段话说明了在大量数据的时候,GloVe比较好的并行实现!
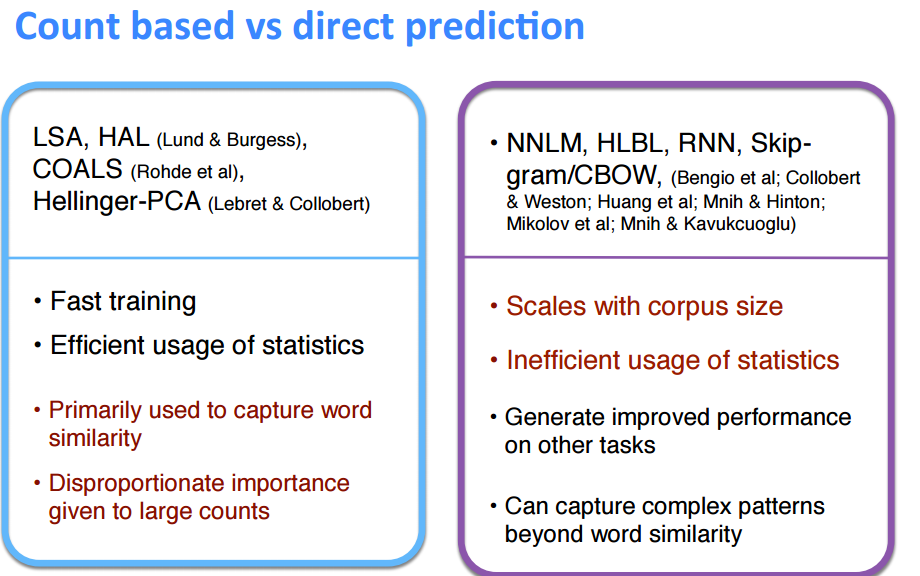
最后,贴一张ppt,讲述Count based模型和direct predicDon模型的区别。
因为在word2vec中,我们知道是有两个向量来表示一个词的,分别是中心词和”旁边“词,但在最后我们只需要一个词向量来代表一个词,下面就说明了怎么来合并这两个词!



下面是介绍词向量的评估,分为两种,一个是内部一个是外部评估:

词向量内部评测方法
词向量内部评测方法主要有词向量类比、词向量相关度,这两种方法有相应的数据集。
词向量类比的基本思想如下:

目前评测的数据集主要是word2vec项目提供的数据集包含了语义类比和语法类比两种。语义类比的数据有州名包含城市名、首都和国家, 语法类比的数据是比较级类比和时态类比。
词向量相关度的数据集例如WordSim353, 该数据集是人为地给两个词的相关度打分(从0-10),然后通过计算词向量的Cosine相似度与 这个相关度进行对比。
词向量外部评测方法
简单来说就是把词向量应用于具体的任务中来评测不同的词向量对于任务整体性能的影响。 这里需要注意的问题是,应用于具体任务的时候是否还需要调整词向量, 一般来说调整词向量会降低向量的范化能力。所以一般具体任务的训练集足够大时才考虑调整词向量。
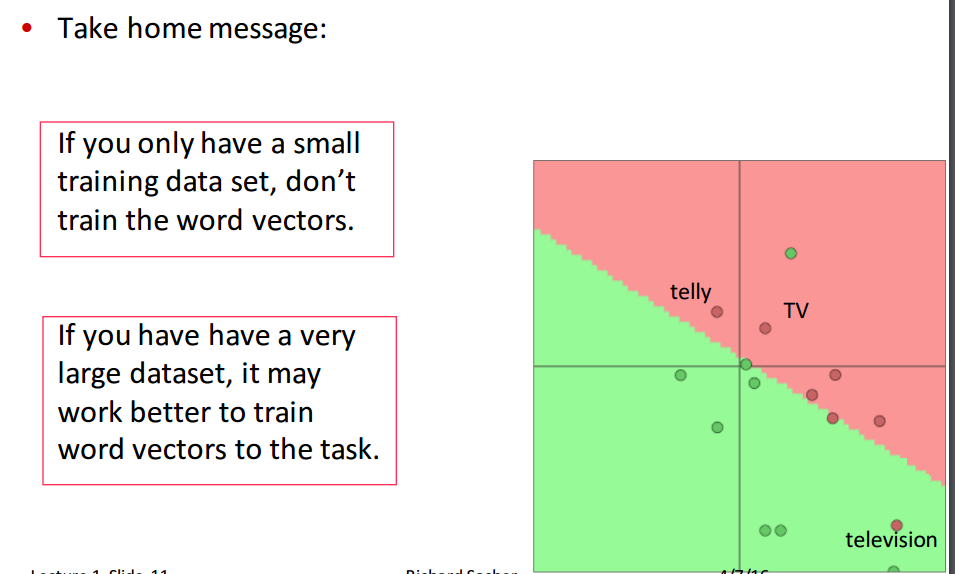
下面课程用一个很简单的额例子说明了在数据量较小的情况下,去训练词向量会使得分类失去泛华能力,这是不可取的!