

欢迎在文章下方评论,建议用电脑看
其实它就是很简单的求导链式法则
有小伙伴可能不是很清楚什么是链式法则,下面进行解释:
先举一个例子: 我们以求e=(a+b)*(b+1)的偏导[3]为例。
它的复合关系画出图可以表示如下:
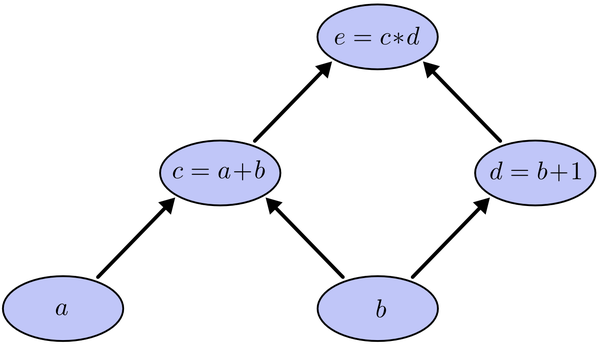
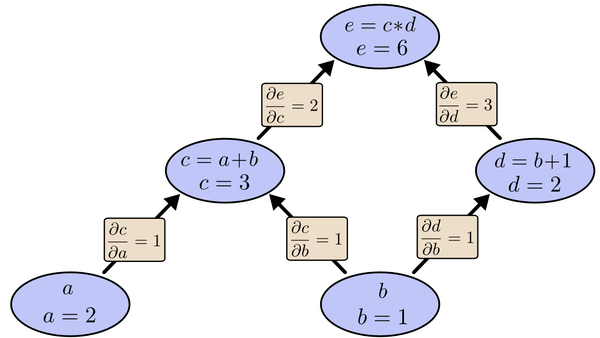
在图中,引入了中间变量c,d。在图中,引入了中间变量c,d。为了求出a=2, b=1时,e的梯度,我们可以先利用偏导数的定义求出不同层之间相邻节点的偏导关系,如下图所示。
利用链式法则我们知道:
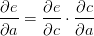
以及
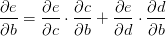
链式法则在上图中的意义是什么呢?其实不难发现,
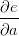 的值等于从a到e的路径上的偏导值的乘积,而
的值等于从a到e的路径上的偏导值的乘积,而的值等于从b到e的路径1(b-c-e)上的偏导值的乘积加上路径2(b-d-e)上的偏导值的乘积。也就是说,对于上层节点p和下层节点q,要求得
,需要找到从q节点到p节点的所有路径,并且对每条路径,求得该路径上的所有偏导数之乘积,然后将所有路径的 “乘积” 累加起来才能得到
的值。
大家也许已经注意到,这样做是十分冗余的,因为很多路径被重复访问了。比如上图中,a-c-e和b-c-e就都走了路径c-e。对于权值动则数万的深度模型中的神经网络,这样的冗余所导致的计算量是相当大的。
同样是利用链式法则,BP算法则机智地避开了这种冗余,它对于每一个路径只访问一次就能求顶点对所有下层节点的偏导值。
正如反向传播(BP)算法的名字说的那样,BP算法是反向(自上往下)来寻找路径的。从最上层的节点e开始,初始值为1,以层为单位进行处理。对于e的下一层的所有子节点,将1乘以e到某个节点路径上的偏导值,并将结果“堆放”在该子节点中。等e所在的层按照这样传播完毕后,第二层的每一个节点都“堆放”些值,然后我们针对每个节点,把它里面所有“堆放”的值求和,就得到了顶点e对该节点的偏导。然后将这些第二层的节点各自作为起始顶点,初始值设为顶点e对它们的偏导值,以”层”为单位重复上述传播过程,即可求出顶点e对每一层节点的偏导数。
以上图为例,节点c接受e发送的12并堆放起来,节点d接受e发送的13并堆放起来,至此第二层完毕,求出各节点总堆放量并继续向下一层发送。节点c向a发送21并对堆放起来,节点c向b发送21并堆放起来,节点d向b发送31并堆放起来,至此第三层完毕,节点a堆放起来的量为2,节点b堆放起来的量为21+3*1=5, 即顶点e对b的偏导数为5.
举个不太恰当的例子,如果把上图中的箭头表示欠钱的关系,即c→e表示e欠c的钱。以a, b为例,直接计算e对它们俩的偏导相当于a, b各自去讨薪。a向c讨薪,c说e欠我钱,你向他要。于是a又跨过c去找e。b先向c讨薪,同样又转向e,b又向d讨薪,再次转向e。可以看到,追款之路,充满艰辛,而且还有重复,即a, b 都从c转向e。
而BP算法就是主动还款。e把所欠之钱还给c,d。c,d收到钱,乐呵地把钱转发给了a,b,皆大欢喜。
一个有趣的现象是在多数情况下,反向传播中的梯度可以被很直观地解释。例如神经网络中最常用的加法、乘法和取最大值这三个门单元,它们在反向传播过程中的行为都有非常简单的解释。先看下面这个例子:
——————————————————————————————————————————
一个展示反向传播的例子。加法操作将梯度相等地分发给它的输入。取最大操作将梯度路由给更大的输入。乘法门拿取输入激活数据,对它们进行交换,然后乘以梯度。
——————————————————————————————————————————
从上例可知:
加法门单元把输出的梯度相等地分发给它所有的输入,这一行为与输入值在前向传播时的值无关。这是因为加法操作的局部梯度都是简单的+1,所以所有输入的梯度实际上就等于输出的梯度,因为乘以1.0保持不变。上例中,加法门把梯度2.00不变且相等地路由给了两个输入。
取最大值门单元对梯度做路由。和加法门不同,取最大值门将梯度转给其中一个输入,这个输入是在前向传播中值最大的那个输入。这是因为在取最大值门中,最高值的局部梯度是1.0,其余的是0。上例中,取最大值门将梯度2.00转给了z变量,因为z的值比w高,于是w的梯度保持为0。
乘法门单元相对不容易解释。它的局部梯度就是输入值,但是是相互交换之后的,然后根据链式法则乘以输出值的梯度。上例中,x的梯度是-4.00x2.00=-8.00。
非直观影响及其结果。注意一种比较特殊的情况,如果乘法门单元的其中一个输入非常小,而另一个输入非常大,那么乘法门的操作将会不是那么直观:它将会把大的梯度分配给小的输入,把小的梯度分配给大的输入。在线性分类器中,权重和输入是进行点积,这说明输入数据的大小对于权重梯度的大小有影响。例如,在计算过程中对所有输入数据样本乘以1000,那么权重的梯度将会增大1000倍,这样就必须降低学习率来弥补。这就是为什么数据预处理关系重大,它即使只是有微小变化,也会产生巨大影响。对于梯度在计算线路中是如何流动的有一个直观的理解,可以帮助读者调试网络。
附上一个维基专业解释
就是在回归那里一样的普通更新方法梯度下降算法
主要注意的是,在深度学习中比较常用的是mini-batch 梯度下降
# 动量更新
v = mu * v - learning_rate * dx # 与速度融合(1)
x += v # 与位置融合
在这里引入了一个初始化为0的变量v和一个超参数mu,物理观点建议梯度只是影响速度,然后速度再影响位置。从公式可以看出,我们通过重复地增加梯度项来构造速度,那么随着迭代次数的增加,速度会越来越快,这样就能够确保momentum技术比标准的梯度下降运行得更快;同时μ的引入,一个典型的设置是刚开始将动量设为0.5而在后面的多个周期(epoch)中慢慢提升到0.99。,保证了在接近谷底时速度会慢慢下降,最终停在谷底,而不是在谷底来回震荡。 所以,由于在公式(1)中,两项都会发生变化,所以导致的后果就是V先增大,后减小。
x_ahead = x + mu * v
# 计算dx_ahead(在x_ahead处的梯度,而不是在x处的梯度)
v = mu * v - learning_rate * dx_ahead
x += v
等价与:
v_prev = v # 存储备份
v = mu * v - learning_rate * dx # 速度更新保持不变
x += -mu * v_prev + (1 + mu) * v # 位置更新变了形式
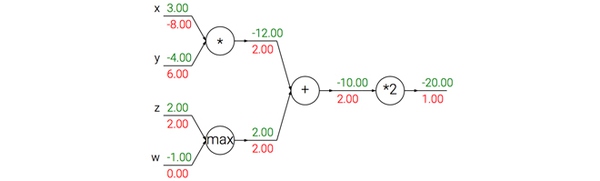
和上面的动量(Momentum)更新差不多,但是,不同的在于,当参数向量位于某个位置x时,观察上面的动量更新公式可以发现,动量部分(忽视带梯度的第二个部分)会通过mu * v稍微改变参数向量。因此,如果要计算梯度,那么可以将未来的近似位置x + mu * v看做是“向前看”,这个点在我们一会儿要停止的位置附近。因此,计算x + mu * v的梯度而不是“旧”位置x的梯度就有意义了。
Nesterov动量。既然我们知道动量将会把我们带到绿色箭头指向的点,我们就不要在原点(红色点)那里计算梯度了。使用Nesterov动量,我们就在这个“向前看”的地方计算梯度。
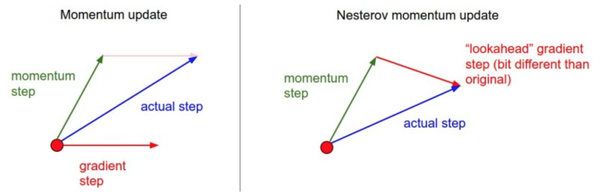
如下图:
在实际应用中,我们通常选择步长衰减,因为它包含的超参数少,计算代价低。
前面讨论的所有方法都是对学习率进行全局地操作,并且对所有的参数都是一样的。学习率调参是很耗费计算资源的过程,所以很多工作投入到发明能够适应性地对学习率调参的方法,甚至是逐个参数适应学习率调参。很多这些方法依然需要其他的超参数设置,但是其观点是这些方法对于更广范围的超参数比原始的学习率方法有更良好的表现。在本小节我们会介绍一些在实践中可能会遇到的常用适应算法:
Adagrad是一个由Duchi等提出的适应性学习率算法
# 假设有梯度和参数向量x
cache += dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
注意,变量cache的尺寸和梯度矩阵的尺寸是一样的,还跟踪了每个参数的梯度的平方和。这个一会儿将用来归一化参数更新步长,归一化是逐元素进行的。注意,接收到高梯度值的权重更新的效果被减弱,而接收到低梯度值的权重的更新效果将会增强。有趣的是平方根的操作非常重要,如果去掉,算法的表现将会糟糕很多。用于平滑的式子eps(一般设为1e-4到1e-8之间)是防止出现除以0的情况。Adagrad的一个缺点是,在深度学习中单调的学习率被证明通常过于激进且过早停止学习。
RMSprop。是一个非常高效,但没有公开发表的适应性学习率方法。有趣的是,每个使用这个方法的人在他们的论文中都引用自Geoff Hinton的Coursera课程的第六课的第29页PPT。这个方法用一种很简单的方式修改了Adagrad方法,让它不那么激进,单调地降低了学习率。具体说来,就是它使用了一个梯度平方的滑动平均:
cache = decay_rate * cache + (1 - decay_rate) * dx**2
x += - learning_rate * dx / (np.sqrt(cache) + eps)
在上面的代码中,decay_rate是一个超参数,常用的值是[0.9,0.99,0.999]。其中x+=和Adagrad中是一样的,但是cache变量是不同的。因此,RMSProp仍然是基于梯度的大小来对每个权重的学习率进行修改,这同样效果不错。但是和Adagrad不同,其更新不会让学习率单调变小。
Adam。有点像RMSProp+momentum,效果比RMSProp稍好,简化的代码是下面这样:
m = beta1*m + (1-beta1)*dx
v = beta2*v + (1-beta2)*(dx**2)
x += - learning_rate * m / (np.sqrt(v) + eps)
注意这个更新方法看起来真的和RMSProp很像,除了使用的是平滑版的梯度m,而不是用的原始梯度向量dx。论文中推荐的参数值eps=1e-8, beta1=0.9, beta2=0.999。在实际操作中,我们推荐Adam作为默认的算法,一般而言跑起来比RMSProp要好一点。但是也可以试试SGD+Nesterov动量。完整的Adam更新算法也包含了一个偏置(bias)矫正机制,因为m,v两个矩阵初始为0,在没有完全热身之前存在偏差,需要采取一些补偿措施。建议读者可以阅读论文查看细节,或者课程的PPT。


