

欢迎在文章下方评论,建议用电脑看
下面来来开始说下这些年最火的ImageNet图像识别模型,当然这里我是在记论文笔记,他们都是卷积神经网络,如果还不知道什么是卷积神经网络的话,请移步到这篇博文
关于深度,其实在ImageNet这个比赛来说,可以说是一年更比一年深,到了2015残差网络,作者在论文中甚至说他试过用1000多层,只是它的效果和100多层的效果差不多,所以也就用可100多层的网络作为最后选择。
下面就是从AlexNet到ResNet的深度变化的直观过程,他们的结构各有特点,下面将一一说明。
论文原文(来源AlexNet):We did not pre-process the images in any other way, except for subtracting the mean activity over the training set from each pixel.So we trained our network on the (centered) raw RGB values of the pixels.
很简单,我们在做图像处理的时候,只需要数据零中心话即可,其实也是深度学习端到端的要义-直接输入原始数据,仅仅需要一个模型,不用很多的预处理,其他模块,然后就可以输出结果,而不是像传统系统,要几个模块的设计(比如:机器翻译 要设计翻译模型 语言模型 调序模型)
论文原文(来源AlexNet):
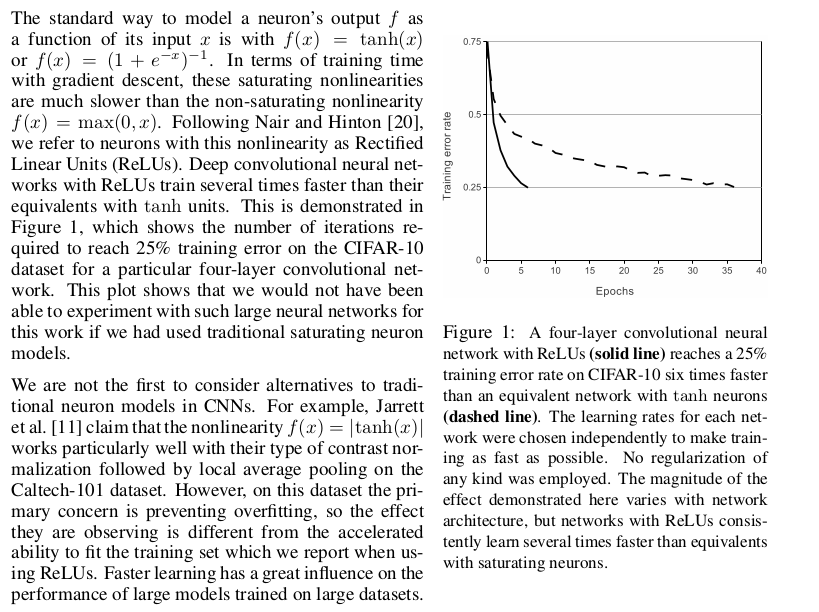
相对与选择那些会饱和的激活函数,例如tanh或者,用ReLU线性激活函数是最快的,从那个图中我们也可以看的出来,而在这个特性在这种深层大型的神经网络中是非常重要的!同时需要注意的是现在大部分的深度神经网络都选择这个为激活函数
论文原文(来源AlexNet):

使用ReLU f(x)=max(0,x)后,你会发现激活函数之后的值没有了tanh、sigmoid函数那样有一个值域区间,所以一般在ReLU之后会做一个normalization,LRU就是稳重提出(这里不确定,应该是提出?)一种方法,在神经科学中有个概念叫“Lateral inhibition”,讲的是活跃的神经元对它周边神经元的影响,这个灵感来源于人体中的神经网络!
论文原文(来源AlexNet):
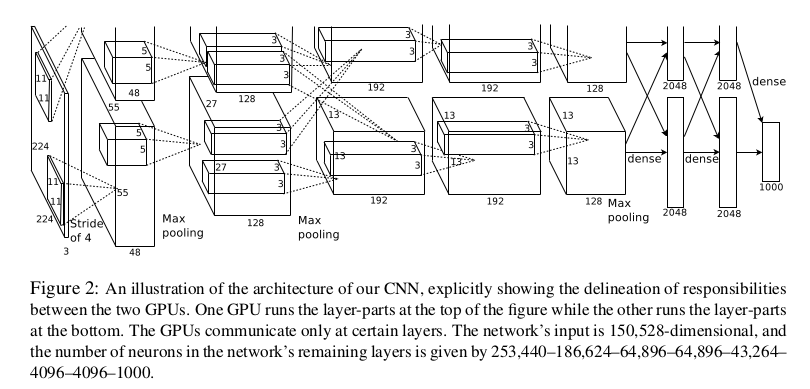
需要注意的是,作者用了两个GPU来进行训练,然后卷积只在某一层进行交叉链接!这样可以加快训练,但效果也不会被影响
论文原文(来源AlexNet): Our ConvNet configurations are quite different from the ones used in the top-performing entries of the ILSVRC-2012 (Krizhevsky et al., 2012) and ILSVRC-2013 competitions (Zeiler & Fergus,2013; Sermanet et al., 2014). Rather than using relatively large receptive fields in the first conv. layers (e.g. 11 × 11 with stride 4 in (Krizhevsky et al., 2012), or 7 × 7 with stride 2 in (Zeiler & Fergus,2013; Sermanet et al., 2014)), we use very small 3 × 3 receptive fields throughout the whole net,which are convolved with the input at every pixel (with stride 1). It is easy to see that a stack of two 3 × 3 conv. layers (without spatial pooling in between) has an effective receptive field of 5 × 5; three

VGGnet其实和一开始的AlexNet在结构上没有什么太大的差别,不同的就是,在第一个卷基层层使用更小的filter尺寸和间隔(kernel size=3, stride=1), AlexNet(kernel size=11, stride=4)。然后更加的深了!这样可以减少参数(文中有举例),并且可以得到更多的特征,经过三层非线性激活函数增加了非线性的特性!
这里说明了1X1卷积核到底有什么作用?在这里说了就是可以在保持feature map 尺寸不变(即不损失分辨率)的前提下大幅增加非线性特性,把网络做得很deep。但对于1X1卷积核,下面下面要将的GoogLeNet和ResNet同样使用了,但那个是用来降维和升维的,具体的下面在讲!
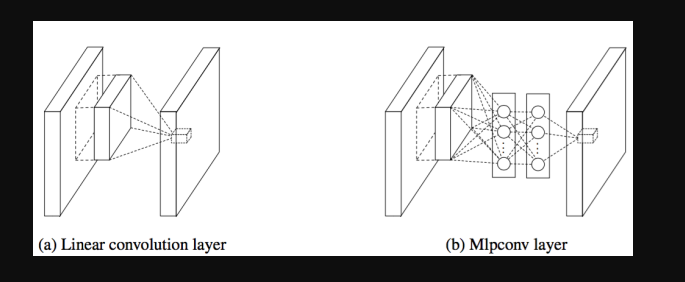
卷积层的改进:MLPconv,在每个local部分进行比传统卷积层复杂的计算,如上图右,提高每一层卷积层对于复杂特征的识别能力,这里举个不恰当的例子,传统的CNN网络,每一层的卷积层相当于一个只会做单一任务,你必须要增加海量的filters来达到完成特定量类型的任务,而MLPconv的每层conv有更加大的能力,每一层能够做多种不同类型的任务,在选择filters时只需要很少量的部分
1×1的卷积层(可能)引起人们的重视是在NIN的结构中,论文中林敏师兄的想法是利用MLP代替传统的线性卷积核,从而提高网络的表达能力。文中同时利用了跨通道pooling的角度解释,认为文中提出的MLP其实等价于在传统卷积核后面接cccp层,从而实现多个feature map的线性组合,实现跨通道的信息整合。而cccp层是等价于1×1卷积的,因此细看NIN的caffe实现,就是在每个传统卷积层后面接了两个cccp层(其实就是接了两个1×1的卷积层)。这就实现跨通道的交互和信息整合
论文原文(来源Network in Network):

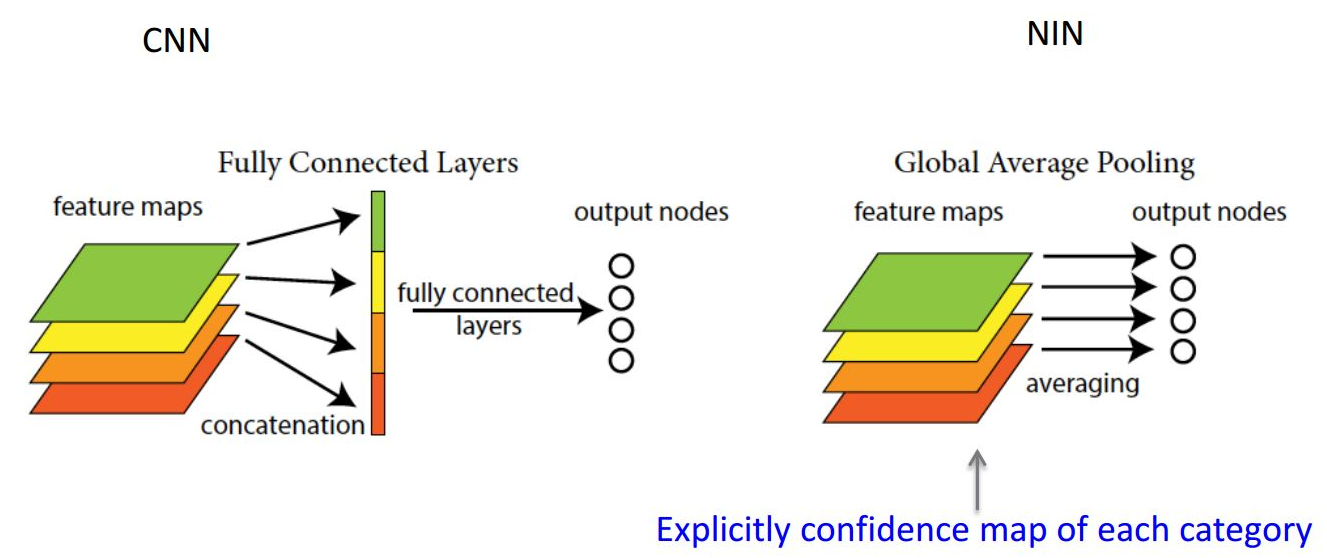
采用全局均值池化来解决传统CNN网络中最后全连接层参数过于复杂的特点,而且全连接会造成网络的泛化能力差,Alexnet中有提高使用dropout来提高网络的泛化能力。
global average pooling 与average pooling的区别:
如最后一个卷积层输出10个feature map,average pooling 是对每个feature map分别求平均,输出10个feature map。 global average pooling是对每个feature map内部取平均,每个feature map变成一个值(因为kernel的大小设置成和feature map的相同),10个feature map就变成一个10维的向量,然后直接输入到softmax中。
其实简单理解就是在原始的CNN中10个feature map的话经过average pooling输出的不一定是一个值,而global average pooling输出的就一定是一个值
下图是直观理解:
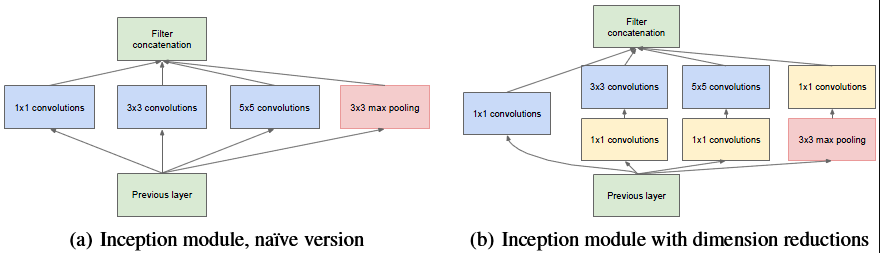
再论1×1卷积的作用以GoogLeNet的3a模块为例,输入的feature map是28×28×192,3a模块中1×1卷积通道为64,3×3卷积通道为128,5×5卷积通道为32,如果是左图结构,那么卷积核参数为1×1×192×64+3×3×192×128+5×5×192×32,而右图对3×3和5×5卷积层前分别加入了通道数为96和16的1×1卷积层,这样卷积核参数就变成了1×1×192×64+(1×1×192×96+3×3×96×128)+(1×1×192×16+5×5×16×32),参数大约减少到原来的三分之一。
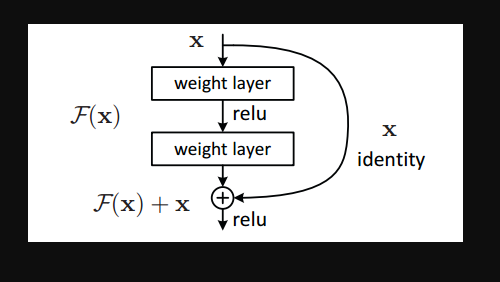
通过求偏导我们就能看到,F(X)就是拟合残差,x就是之前的函数结果,两个相加就可以得到更加好的结果。
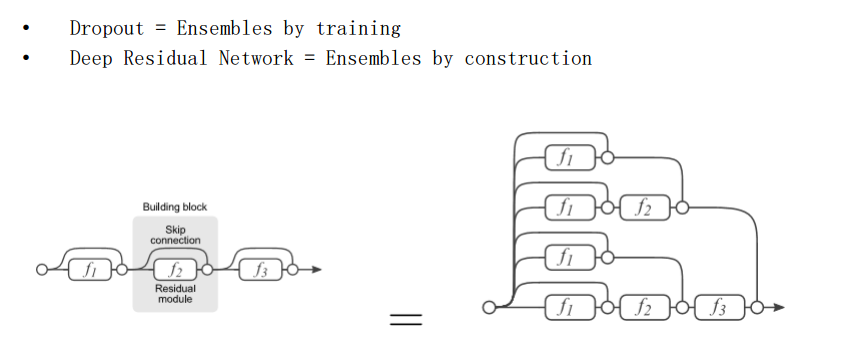
我们发现,其实残差网络和dropout有类似的功能,其实也可以用上面的图,一条路径就代表这一个网络的话,那么就是和dropout类似的,这样集成正则化的方式,也是能有效采用这样的加深网络的方式来提升模型性能。
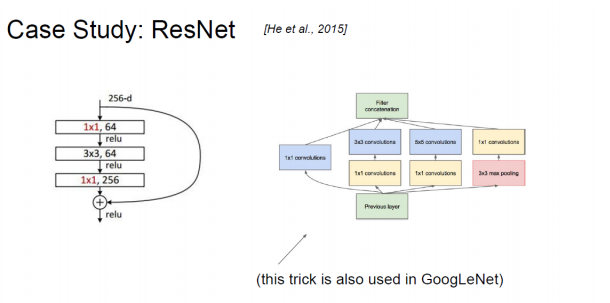
ResNet同样也利用了1×1卷积,并且是在3×3卷积层的前后都使用了,不仅进行了降维,还进行了升维,使得卷积层的输入和输出的通道数都减小,参数数量进一步减少.


