

建议用电脑看
本文使用监督学习和强化学习的技术以端到端的方式训练完成任务型的对话系统,主要的贡献有以下三点:
1.鲁棒性:本文提出一种神经对话系统,具有更强的鲁棒性,能够根据强化学习在未知的情况下自动选择用户的动作;
2.灵活性:允许用户在对话过程中发起对话,使用户可以更加灵活的与系统进行交互,;(也就是可以自己定义动作?,不太理解。。。)
3.可重现性:本文演示了如何使用任务特定数据集并模拟用户以端到端方式评估RL对话代理,从而确保了系统的可重现性。有自己开源的代码,并且凸显出在各种任务上的都可以迁移。
系统框架:
该系统主要由用户议程模型、自然语言生成模块、语义理解模块、对话管理模块几部分组成,系统框图如下:
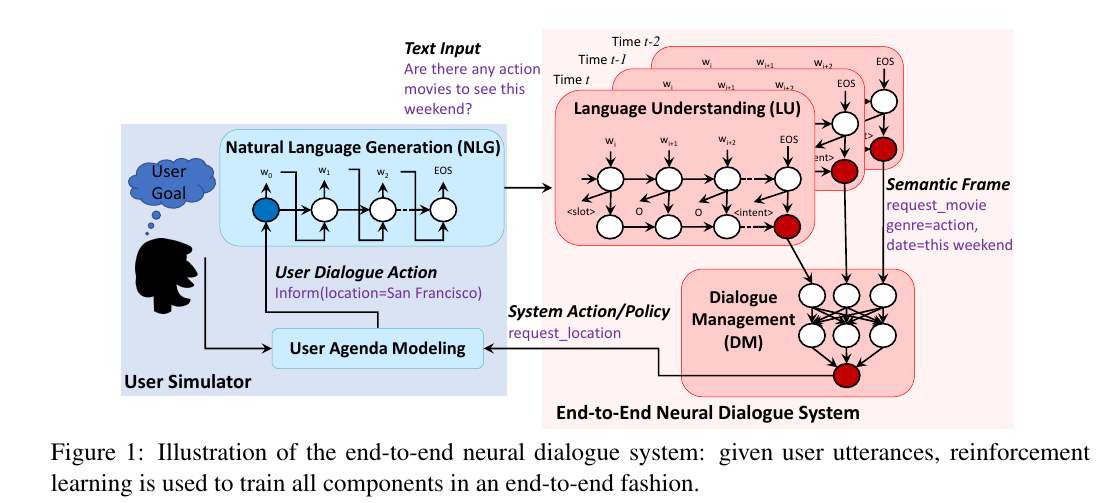
1.用户议程模型
在对话过程中,用户模拟器包含一个紧凑的类似与堆栈的表示,这就是用户的议程,在这过程中用户的状态s_{u} 作为议程A和目标G的决定因素,其中目标G是由限制集合C和请求集合R成。在时间为t的每一步时间段内,用户模拟器根据用户当前的状态s_{u,t} 和上一节点多用户代理的动作a_{m,t-1} 来预测下一用户的动作a_{u,t} 从而更新该时刻用户的状态s’_{u,t} 。
2.自然语言生成(NLG)
自然语言生成:即根据用户的对话行动,生成自然语言文本。为了控制给定有限的标记数据的用户模拟的质量,本文采用包括基于模板的NLG和基于模型的NLG的混合方法,其中基于模型的NLG使用序列到序列模型在标记的数据集上训练。它采用对话行为作为输入,并通过LSTM解码器产生具有插槽占位符的句子草图。然后执行后处理扫描,以将槽位占位符替换为它们的实际值。在LSTM解码器中,我们应用波束搜索,其在生成下一个令牌时迭代地考虑前k个最佳子句。
在这个混合的模型中,如果用户对话的动作可以在预先设置的语句模板中找到的话,系统就是用基于模版的NLG,否则的话,系统就采用基于模型的NLG。这种混合的方法通过提供简单的模板从而提高了NLG的性能,而这正是机器学习不能够很好支持的地方。
3.语意理解模块(LU)
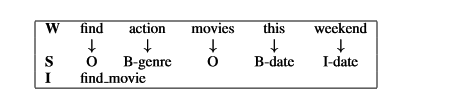
语言理解(LU):LU的一个主要任务是自动将用户的查询域与该域中特定的意图一起分类,并在一组时隙中填充以形成语义帧。流行的IOB(in-out-begin)格式用于表示槽标签。LU组件由单个LSTM实现,该单个LSTM同时执行意图预测和槽缝填充。使用反向传播训练LSTM模型的权重以最大化训练集标签的条件似然概率。预测标签集是IOB格式槽标签和意图标签的级联集合;因此,可以使用监督方式在标记的数据集中使用所有可用的对话动作和对话对来训练该模型。IOB格式标签示例如下:
4.对话管理模块(DM)
| 符号LU输出以对话行为形式(或语义帧)传递到DM。经典DM包括两个阶段,对话状态追踪和策略的学习。给定LU符号输出,形成查询以与数据库交互以检索可用结果。状态跟踪器将根据数据库的可用结果和最新的用户对话操作进行更新。然后跟踪器准备策略学习的状态表示,其中包括最近的用户动作,最新代理动作,数据库结果,转向信息以及历史对话轮次等。在从状态跟踪器输入的状态上,策略学习是生成下一个可用的系统动作\pi (s | a)。 |
端到端的强化学习:
本文采用强化学习的方式,以端到端的训练方式,来学习得到系统的策略。策略决策方式采用DQN算法(Deep Q Learning),将用户的状态s_{t} 作为状态跟踪器的输入,输出Q(s_{t} ,a;\theta )。其中应用了DQN的两个重要的方法:目标网络的使用和经验池的回放(经验池的回放策略可以在对话的设置中进行改变)。
在训练过程中,使用了\epsilon -greedy算法来进行探索和具有动态改变缓冲区大小的经验重放缓冲区。在每个模拟对话中,系统模拟N个对话并将这些状态转化为四元组(s_{t} ,a_{t} ,r_{t} ,s_{t+1} )添加到经验缓冲区中以用于训练。在一次模拟时隙中,当前的DQN网络将被更新许多次(根据batch的大小和当前经验缓冲区的大小)。在最后一次模拟时隙中,目标网络将被替换成当前的DQN网络。
经验回放策略对于强化学习是十分重要的,因此该系统采用了一种热启动的方式来进行经验回放。一般来说,我们认为DQN的初始性能不足以产生良好的经验重放元组,一次我们不会将其放到经验池中,知道RL代理道道一定的成功率之后在放到经验池中(例如:可以先用规则的代理产生经验重放元组)。在每次的模拟中,该系统估计当前DQN代理的成功率(通过多次模拟用户),如果当前DQN代理由于目标网络,则经验回放缓冲池将被激活。
实验和讨论:
该系统是一个任务型对话系统,任务是帮助用户预定电影票。在对话过程中,对话系统收集用户的欲望信息,并最终预定电影票。然后环境基于(1)电影是否被预订以及(2)电影是否满足用户约束,在对话结束二元结果(成功或失败)。原始对话数据由Amazon Mechanical Turk得到,总共标记了280个对话,平均对话圈数约为11。
在DM训练中进行了两组实验,即采用两种输入格式来训练RL代理:(1)语义帧:基于用户动作的语义帧训练或测试策略时,使用噪声信道用于模拟用户和代理之间的LU错误和噪声通信的噪声。(2)自然语言:当训练或测试自然语言层面的政策时,LU和NLG可能引入噪声。实验的结果如下图所示:
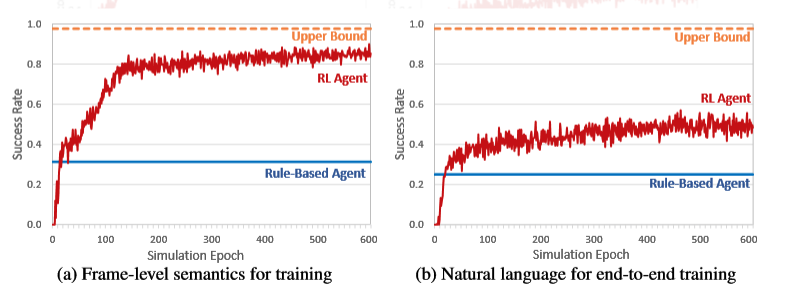
从结果来看,RL代理明显优于基于规则的代理,显示了神经对话系统的潜力,可以完成显示世界的任务,并通过与用户的交互自主的进行改进。此外对比两图可以看出端到端的系统达到稳定需要更长的时间来适应LU和NLG的噪声,这表明维持系统的鲁棒性的困难。而该系统与上述困难一致的增长趋势也更好的表明了该系统在现实生活应用情境下的鲁棒性。
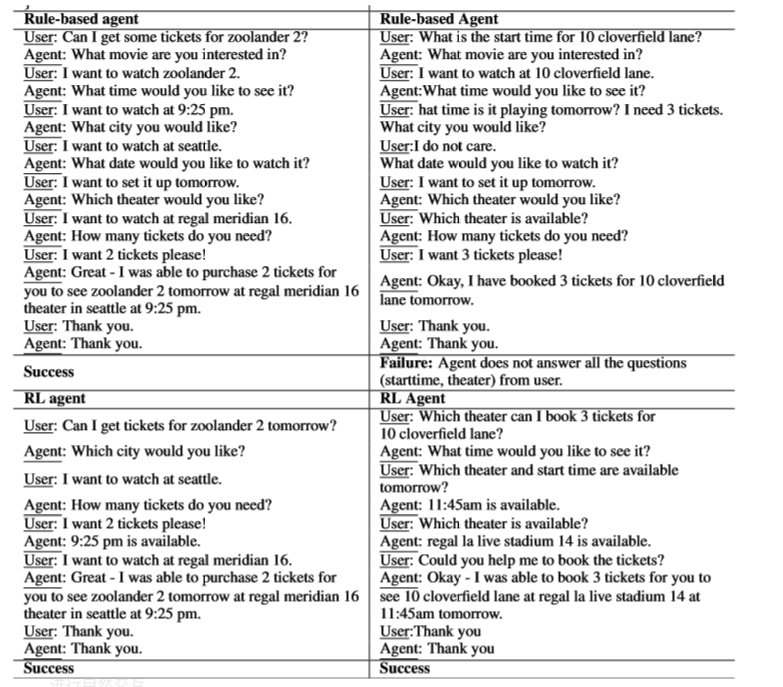
系统得到的对话结果如下(基于规则的代理和RL代理):
之前的end to end,比如基于Memory network的那个模型,因为他们是sl来训练的,这样就需要大量的数据,不然就很容易过拟合。
本文提出了一种端到端学习框架,用于任务完成对话系统。 我们的实验表明,强化学习系统的性能优于基于规则的代理,并具有更好的鲁棒性,以允许在真实世界任务完成方案中与用户进行自然交互。


