

建议用电脑看
1.Dialogue的状态是隐藏在LSTM里了。这样可以Model非常多的状态。
2.结合了传统的Supervised Learning的Tracking模式和RL的模式。
3.模型是端到端训练,和传统的有很大的不同。
4.程序员的接口定义得相对比较清晰。
文章的开头很有意思,先是从一个大家熟知的场景开始介绍,一个经验丰富的客服是如何带一个新入职的客服。四个阶段:
1、告诉新客服哪些”controls”是可用的,比如:如何查找客户的信息,如何确定客户身份等等。 2、新客服从老客服做出的good examples中模仿学习。 3、新客服开始试着服务客户,老客服及时纠正他的错误。 4、老客服放手不管,新客服独自服务客户,不断学习,不断积累经验。
本文的框架就是依照上面的过程进行设计的:
1、开发者提供一系列备选的actions,包括response模板和一些API函数,用来被bot调用。(这个也就是需要外界给模型的一些数据) 2、由专家提供一系列example dialogues,用RNN来学习。 3、用一个模拟user随机产生query,bot进行response,专家进行纠正。 4、bot上线服务,与真实客户进行对话,通过反馈来提高bot服务质量。
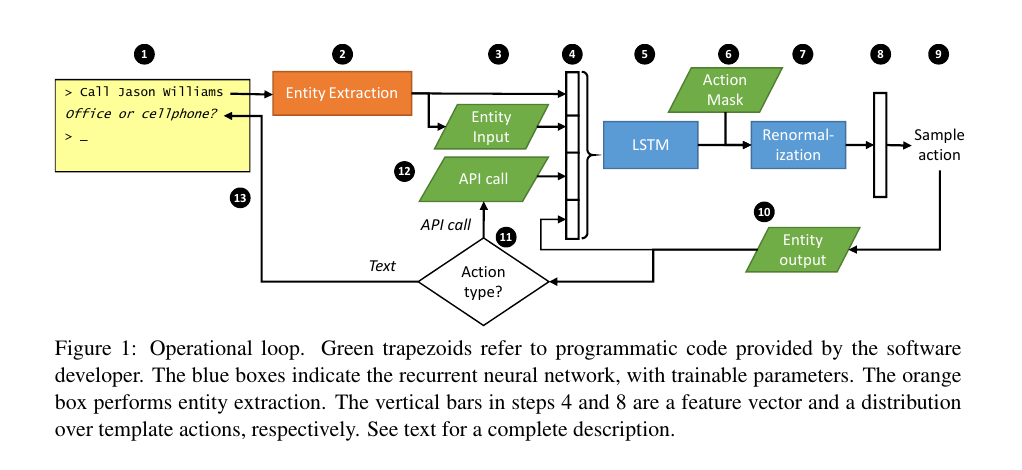
three components of our model are a recurrent neural network; targeted and well-encapsulated software implementing domain-specific functions; and a language understanding module.
共13步:
那么在这个系统中,分工如下是这样的。开发程序员,需要提供(6)、(12)、(13也就是response模板)以及Entity Input(3)和Entity Output(10)(这里也就是数据库)。领域专家需要提供少量(这里是20个,这样必然很容易过拟合,文中给的也是语法结构非常简单的样本)对话样本。然后LSTM可以通过Supervised Learning的方法学习或者通过Reinforcement Learning中的Policy Gradient来进行交互式学习。
在task-oriented dialog systems中,有两个主要的问题,分别是 state tracking和action selection。state tracking表示的是之前的关键信息,而action selection表示的在之后的一个行为选择,这两个步骤都涉及到了一些外部的数据


