建议用电脑看
NLTK(开源中文自然语言处理工具包)包含多种语料库,也可以使用自己的语料库,具体的查看NLTK语料库
nltk提供了比较好的英文标注,中文的话只有繁体的,但中文中有比较强的一种叫做jiaba的分词工具,也可以做到词性标注的目的。当然也可以自动标注。 具体查看词性标注
对于一句话有分词,词性标注,语法文法分析
有三个重要模块:提问处理模块、检索模块、答案抽取模块
查询关键词生成:查询关键词生成,就是从你的提问中提取出关键的几个关键词,因为我本身是一个空壳子,需要去网上查找资料才能回答你,而但网上资料那么多,我该查哪些呢?所以你的提问就有用啦,我找几个中心词,再关联出几个扩展词,上网一搜,一大批资料就来啦,当然这些都是原始资料,我后面要继续处理。
答案类型确定:再说答案类型确定,这项工作是为了确定你的提问属于哪一类的,如果你问的是时间、地点,和你问的是技术方案,那我后面要做的处理是不一样的。
句法和语义分析:最后再说这个句法和语义分析,这是对你问题的深层含义做一个剖析,比如你的问题是:聊天机器人怎么做?那么我要知道你要问的是聊天机器人的研发方法
检索模块跟搜索引擎比较像,就是根据查询关键词所信息检索,返回句子或段落,这部分就是下一步要处理的原料
答案抽取模块可以说是计算量最大的部分了,它要通过分析和推理从检索出的句子或段落里抽取出和提问一致的实体,再根据概率最大对候选答案排序,注意这里是“候选答案”噢,也就是很难给出一个完全正确的结果,很有可能给出多个结果,最后还在再选出一个来
1)海量文本知识表示:网络文本资源获取、机器学习方法、大规模语义计算和推理、知识表示体系、知识库构建;
2)问句解析:中文分词、词性标注、实体标注、概念类别标注、句法分析、语义分析、逻辑结构标注、指代消解、关联关系标注、问句分类(简单问句还是复杂问句、实体型还是段落型还是篇章级问题)、答案类别确定;
3)答案生成与过滤:候选答案抽取、关系推演(并列关系还是递进关系还是因果关系)、吻合程度判断、噪声过滤
现在的主要是基于自然语言理解就是把浅层分析加上句法分析、语义分析都融入进来做的补充和改进。然后形成一个聊天机器人
对话系统按功能性分为goal-driven dialog system(比如功能机器人,Contana,出门问问)和open domain dialog system(比如闲聊机器人,小冰)。
依据答案的不同数据来源,问答系统可划分为基于结构化数据的问答系统、基于自由文本的问答系统、以及基于问答对的问答系统。
此外,按照答案的生成反馈机制划分,问答系统可以分为基于检索式的问答系统和基于生成式的问答系统。
(下面的图片来来自ppt)
主要分成四个部分,如下图:

现在若是这样的一段话:

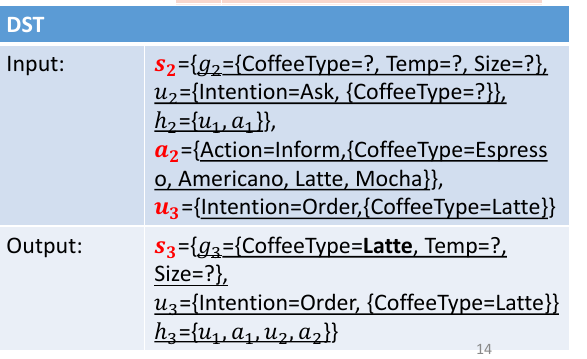
下面就是每个小任务的输入输出和作用:

这里现在的解决方式主要集中于slot-filling problem,因为 Intention Classification是比较简单的分类。
Slot-filling Method: CRF


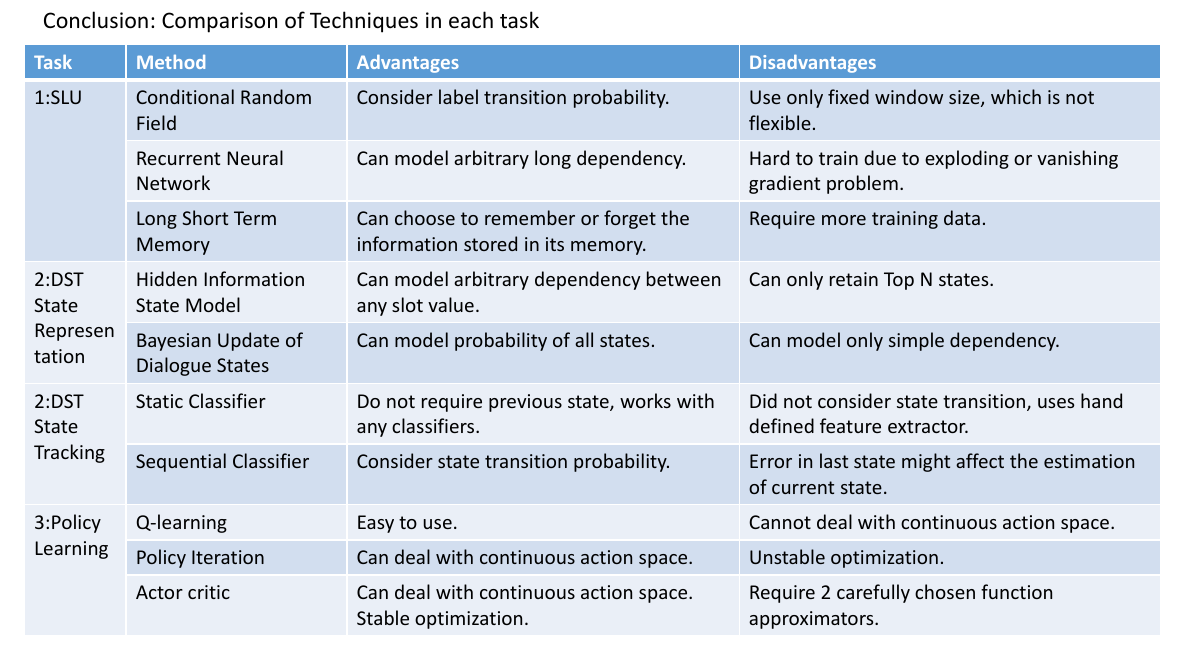
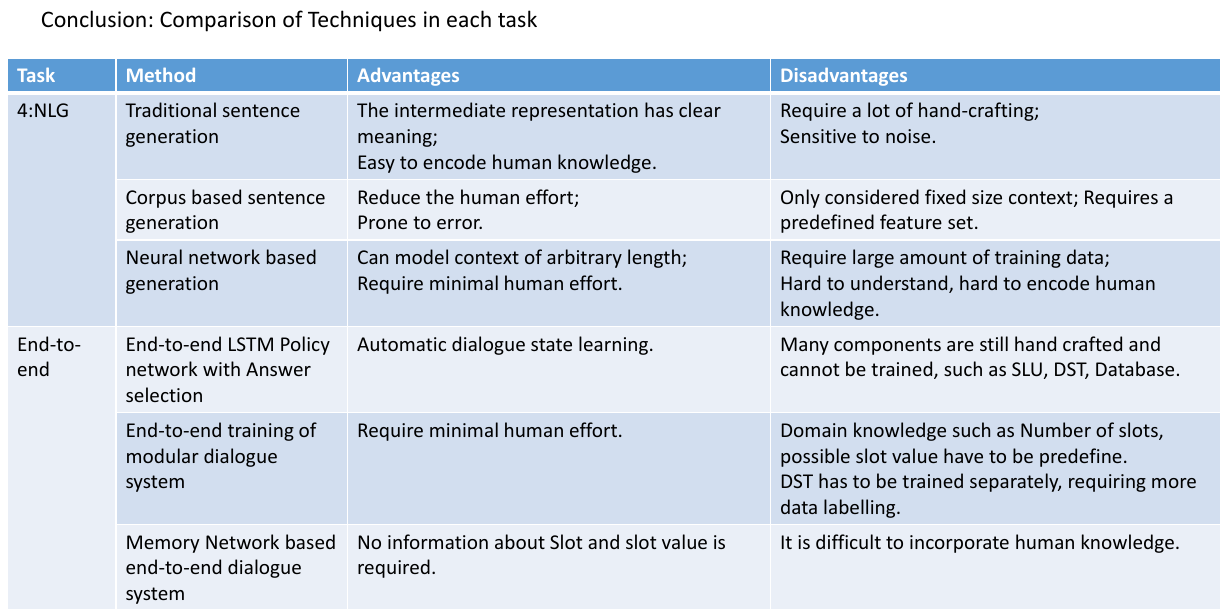
然后其实,在每一个阶段都是有很多不同的方法来达到一个比较好的结果,下面就是一览表。
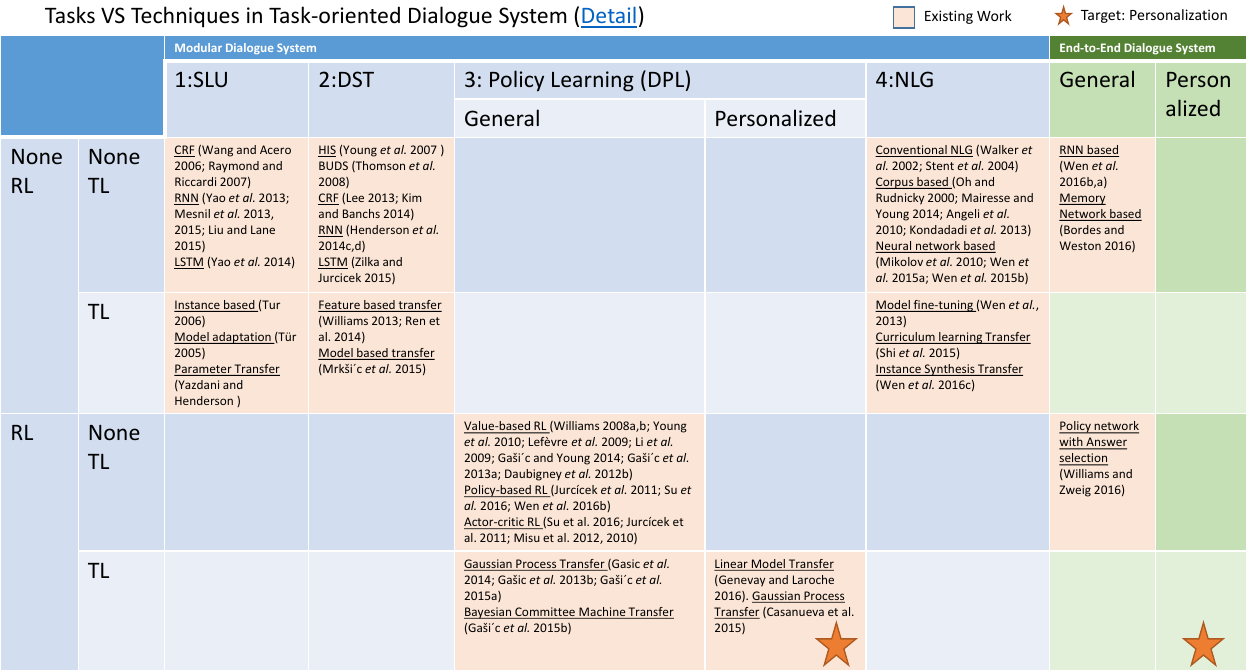
但随着end To end 的发展,现在也有一些模型是直接end To end的模式的。我做的话也应该是end to end的模式的。至于他们之间方法的比较详细请看下面的表