

建议用电脑看
混合代码网络(HCN)最大的特色是在传统的端对端训练中,通过软件编程引入领域知识模块和行为模板,仅需更少训练数据,就取得同等甚至更优成绩。
实验证明,HCN可以通过监督学习,强化学习或两者的混合进行优化。
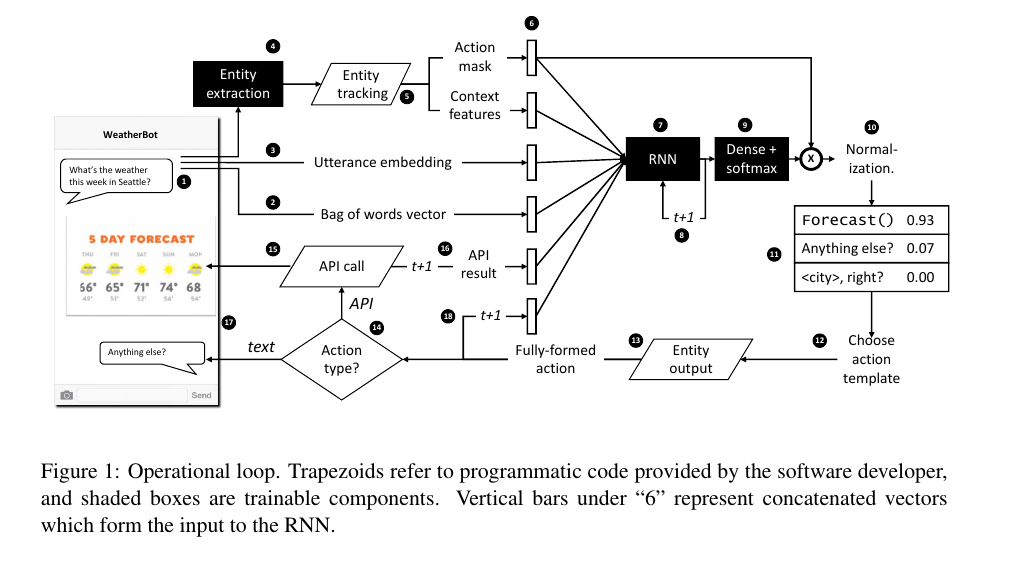
模型包含四部分:RNN, domain-specific software, domain-specific action templates, a conventional entity extraction module. 行为模板可以是文字对话或者调用API。
下面介绍模型的工作流程:
框架从步骤1输入对话开始,分别得到句子的词袋向量,句子的embedding;从实体抽取模块抽取实体,通过“实体追踪”模块追踪实体值,返回动作掩码(action mask),指示在当前时序中哪一个动作被允许执行,比如当目标电话号码未知时,打电话的API将会被禁止,动作掩码可以作为辨别动作有用的上下文特征。以上得到的特征向量拼接作为RNN的输入。RNN之后经过密连接层和softmax,输出向量维度为动作模板的数量,与Action mask点乘,结果的概率重新进行规范化。步骤12选择行为,如果训练用RL的探索模式,行为是所有可能的动作采样;否则挑选最大概率的动作执行。之后在“实体输出”模块,替换上具体实体值,组织回答句子;控制分支根据行为类别不同调用API或者返回文本应答,整个循环完成。
现在的模型和之前不同的地方在于所使用的RNN不仅可以储存之前的状态和选择下一步的动作(也就是生成的下一个bot的对话动作),在HCN中,rnn使用 developer-provided 的action templates,这样可以降低模型的复杂度。
非端到端在Task-oriented dialog systems中的缺点在于complexity,还有就是每个阶段的训练都需要specialized labels。
但同时端到端的话lack a general mechanism for injecting domain knowledge and constraints。也就是领域知识很难被模型吸收。


