欢迎在文章下方评论,建议用电脑看
前面我们已经讲过强化学习。强化学习是求累积回报期望最大时的最优策略,在求解过程中立即回报是人为给定的。然而,在很多任务中,尤其是复杂的任务中,立即回报很难指定。那么该如何得到这些回报函数呢?
因为在利用强化学习算法的时候,我们都假设回报函数是人为给定的。回报函数如何给定呢?这有很强的主观性和经验性。回报函数的不同会导致最优策略的不同。所以回报函数非常重要。但是当任务很复杂时,我们往往难以人为给出回报函数。比如在自动驾驶中,回报函数可能是信号灯、前面汽车,周边环境等各个因素的函数,我们很难人为给定这个回报函数。而且,在执行不同的任务时,回报函数也不同。所以,回报函数是阻碍强化学习算法得到普遍应用的一大障碍。逆向强化学习就是为解决学习回报函数的问题而提出来的。只有解决了这个问题,强化学习算法才能得到大规模应用。
我们人类在完成复杂的任务时,根本就没考虑回报函数。但是,这并不是说人在完成任务时就没有回报函数。可以这么说,其实人在完成具体任务时有隐形的回报函数。所以,一种指定回报函数的方法是从人的示例中学到隐形的回报函数。
可是,这种回报函数怎么学呢?
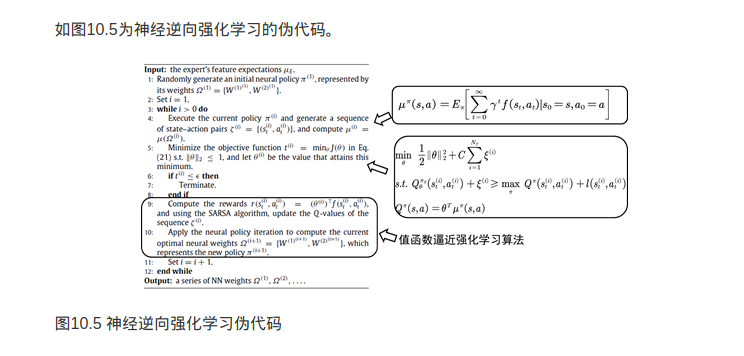
这就需要进行建模了。逆向强化学习的提出者Ng是这么想的:专家在完成某项任务时,其决策往往是最优的或接近最优的,那么可以这样假设,当所有的策略所产生的累积回报期望都不比专家策略所产生的累积回报期望大时,强化学习所对应的回报函数就是根据示例学到的回报函数。
因此,逆向强化学习可以定义为从专家示例中学到回报函数。
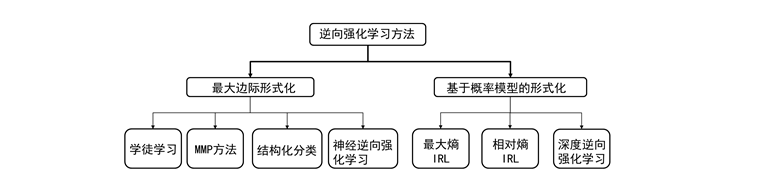
如果将最开始逆向强化学习的思想用数学的形式表示出来,那么这个问题可以归结为最大边际化问题。如图10.1所示,这是强化学习最早的思想。根据这个思想发展起来的算法包括:学徒学习(Apprenticeship learning),MMP方法(Maximum Margin Planning),结构化分类(SCIRL)和神经逆向强化学习(NIRL).
最大边际形式化的最大缺点是很多时候不存在单独的回报函数使得专家示例行为既是最优的又比其他任何行为好很多,或者有很多不同的回报函数会导致相同的专家策略,也就是说这种方法无法解决歧义的问题。
基于概率模型的方法可以解决歧义性的问题。学者们利用概率模型又发展出了很多逆向强化学习算法,如最大熵逆向强化学习、相对熵逆向强化学习、最大熵深度逆向强化学习,基于策略最优的逆向强化学习等等。
其实逆向强化学习来源于模仿学习。模仿学习本身是一个很大的主题。小孩子在学习走路的时候,模仿大人们进行学习。人在学习很多技能的时候都是从模仿开始的。但有人只模仿到了表面,而有人模仿到了精髓。最早的模仿学习是行为克隆,它只模仿到了表面。在行为克隆中,人的示例轨迹被记录下来,下次执行时恢复该轨迹。行为克隆的方法只能模仿轨迹,无法进行泛化。而逆向强化学习是从专家(人为)示例中学到背后的回报函数,能泛化到其他情况,因此属于模仿到了精髓。