欢迎在文章下方评论,建议用电脑看
Actor-critic methods : 许多RL方法 (e.g., policy gradient) 只作用于policy 或者 value function。Actor-critic方法则结合了policy-only和value function-only 的方法。 其中critic用来近似或者估计value function,actor 被称为policy structure, 主要用来选择action。Actor-critic是一个on-policy的学习过程。Critic模型的结果用来帮助提高actor policy的性能。
GAN和actor-critic具有许多相似之处。Actor-critic模型中的actor功能类似于GAN中的generator, 他们都是用来take an action or generate a sample。Actor-critic模型中的critic则类似于GAN中的discriminator, 主要用来评估 actor or generator 的输出。这篇论文主要贡献在于从不同的角度来说明了GAN和actor-critic模型的相同与不同点,从而鼓励研究GAN的学者和研究actor-critic模型的学者合作研发出通用、稳定、可扩展的算法,或者从各自的研究中获取灵感。
Both GANs and AC can be seen as bilevel or two-time-scale optimization problems, where one model is optimized with respect to the optimum of another model:
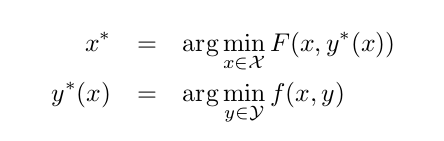
他们的共同思想都是互相优化,其中一个模型的优化关于另个的最优。
In some AC methods, the critic provides a lower-variance baseline for policy gradient methods than estimating the value from returns. In this case even a bad estimate of the value function can be useful, as the policy gradient will be unbiased no matter what baseline is used. In other AC methods, the policy is updated with respect to the approximate value function, in which case pathologies similar to those in GANs can result. If the policy is optimized with respect to an incorrect value function, it may lead to a bad policy which never fully explores the space, preventing a good value function from being found and leading to degenerate solutions.
有一类AC方法会可以给policy gradient methods提供比评估价值函数更小的基准方差的价值回报,这个时候就算是不好的评估也是有用的,因为其实无bais的(//TODO)。
而另外的一类中,评估价值函数会直接影响policy gradient methods,这一类就类似于GANS。也就是critic网络或者GAN中的D网络的评价直接会影响actor或者GAN中的G网络,正向的评价会使得网络变得更好,但是不好的评估回报也会导致不好的引导。
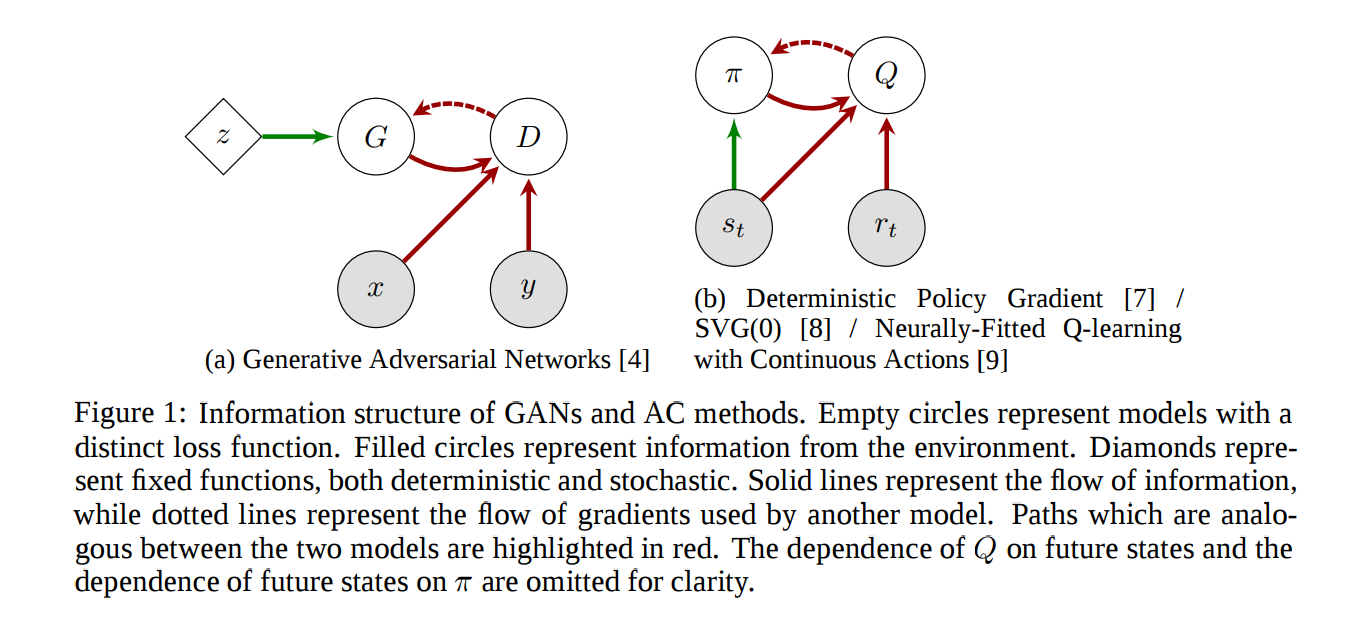
GANs can be seen as a modified actor-critic method with blind actors in stateless MDPs.


两者的G网络/actor网络在优化的时候都是用D网络或者critic网络提供的梯度信息
GANS可以看作是状态无限,然后actors是blind的一种特殊的MDP。原因是:在这里动作集合就是在每个像素生成器所给的值,状态就是生成的图片,因为生成图片的是无关联的,也就是现在生成的图片和未来生成的图片无关,这就导致了状态的无限性(也就是在任何的pixel上的数值是连续的,也就是体现在生成图片的无限性)。actors是blind是因为它不知道环境的任何状态知识。还有就是当给系统展示real image的时候,actor应该参数不变,在GANS体现在达到均衡吧,这个时候生成器就不改变它的权重了(我觉得)。在actor-critic中体现的就是reword为一是,参数不需要太大的改变。
当然他们之间存在不同点:AC算法并不是同一个loss在不同方向上的优化,所用的loss函数不同的。gradient的来源也不同,更新actor-critic更像是正交而不是对抗的(在最后一段),GANS对环境是部分观测的,具体看第二段和第三段。
GAN和AC算法都是不稳定的
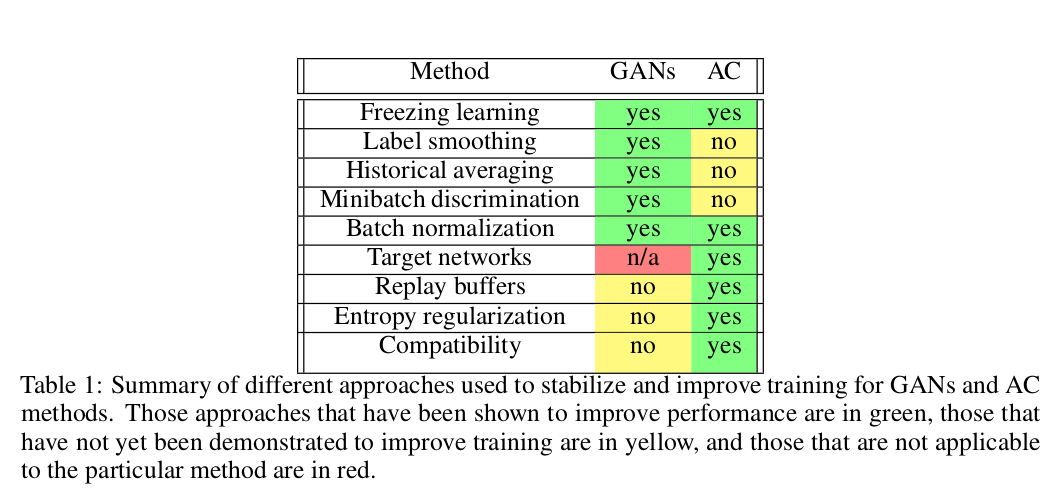
Having reviewed the basics of GANs, actor-critic algorithms and their extensions, here we discuss the “tricks of the trade” used by each community to make them work. The different methods are summarized in Table 1. While not meant as an exhaustive list, we have included those that we believe have either made the largest impact in their fields or have the greatest potential for crossover between fields.