

欢迎在文章下方评论,建议用电脑看
看图说话。就像老师要求小朋友们在看图说话作业中完成的任务一样,我们也希望算法能够根据图像给出能够描述图像内容的自然语言语句
当前水平:貌似接近人类,其实差距尚大。,只是由于评判标准的问题,在一些论文中说差不多接近人类或者说差不多超过人类,但所用的评价标准似乎不那么的,自动评价标准的目前都是尽量让自己的计算结果能够和人类判断结果相关。评价标准是一个问题,这个值得思考!
意义和价值:图像标注问题如果能够得到很好的解决,那么价值是显而易见的,可以应用到图像检索,儿童教育和视力受损人士的生活辅助等方面。而从学术的角度来看,当前图像标注问题的研究,促使人工智能领域的两大领域,计算机视觉和自然语言处理很好地结合,这种跨子领域的结合能够催生出更让人惊艳的方法吗?
首先是:Microsoft COCO Caption数据集,在Microsoft COCO Captions: Data Collection and Evaluation Server中,作者们详细介绍了他们基于MS COCO数据集构建MS COCO Caption数据集的工作。现在大部分论文也是按照这个数据集来做实验的。
然后Flickr8K和30K:数据量上的劣势,确实使Flickr数据集正逐渐失宠,14年论文中几乎都使用,现在一些高水平论文仅在补充文档中展示甚至不采用
PASCAL 1K:是大名鼎鼎的PASCAL VOC challenge图像数据集的一个子集,每张图像人工标注了5个描述语句。一般说来,这个数据集只是用来测试的。
perplexity定义为:
images_Perplexity
在图片标注领域来说,好的例子请看这篇博文
将每个单词的可能性都降低一些,就会发现perplexity值会升高。这就说明:当模型对于下一个生成单词的确信程度降低时,perplexity值反而升高。我们当然是期望一个模型对于它预测的单词能比较有把握啊,所以perplexity值是越低越好。也就是说,这个分数越低,那困惑度就越低,模型也就越好。
BLEU是Bilingual Evaluation Understudy的缩写。这个计算标准在图像标注结果评价中使用是很广泛的,但是它的设计初衷并不是针对图像标注问题,而是针对机器翻译问题,它是用于分析待评价的翻译语句和参考翻译语句之间n元组的相关性的。直白地来说,它的核心思想就是:机器翻译语句与人类的专业翻译语句越接近就越好。一句话:BLEU得分越高越好。
ROUGE是一个设计用来评价文本摘要算法的自动评价标准集,其中有3个评价标准,分别是ROUGE-N,ROUGE-L和ROUGE-S。一句话:ROUGE得分越高越好。
METEOR是用来评价机器翻译输出的标准。该方法基于一元组的精度和召回的调和平均(Harmonic mean),召回的权重比精度要高一点。这个标准还有一些其他标准没有的特性,设计它是为了解决BLEU存在的一些问题。它与人类判断相关性高,而且和BLEU不同,它不仅在整个集合,而且在句子和分段级别,也能和人类判断的相关性高。在全集级别,它的相关性是0.964,BLEU是0.817。在句子级别,它的相关性最高到了0.403。
一句话:METEOR得分越高越好。
CIDEr是专门设计出来用于图像标注问题的,它是通过对每个n元组进行Term Frequency Inverse Document Frequency (TF-IDF) 权重计算,来衡量图像标注的一致性的
一句话:CIDEr得分越高越好。
其实时间也并不长,将CNN和RNN结合的模型用于解决图像标注问题的研究最早也就从2014开始提出,在2015年开始对模型各部分组成上进行更多尝试与优化,到2016年CVPR上成为一个热门的专题。
在这个发展中,将RNN和CNN结合的核心思路没变,变化的是使用了更好更复杂的CNN模型,效果更好的LSTM,图像特征输入到RNN中的方式,以及更复合的特征输入等。正由于其发展时间跨度较短,通过阅读该领域的一些重要文章,可以相对轻松地理出大牛们攻城拔寨的思路脉络,这对我们自己从事研究的思路也会有所启发

模型的结构如下:
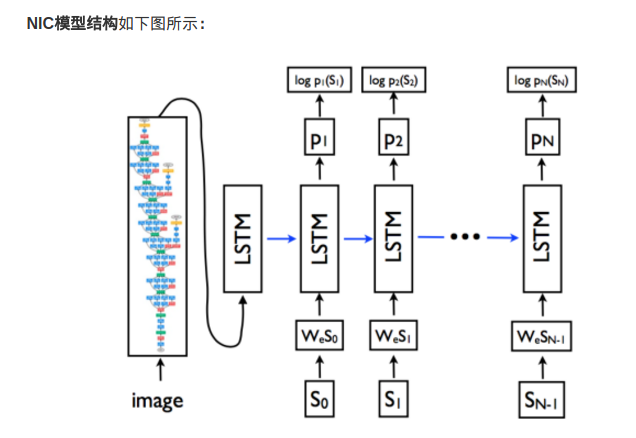
图像特征部分是换汤不换药:我们可以看见,图像经过卷积神经网络,最终还是变成了特征数据(就是特征向量)出来了。唯一的不同就是这次试用的CNN不一样了,取得第几层的激活数据不一样了,归根结底,出来的还是特征向量;
但是!图像特征只在刚开始的时候输入了LSTM,后续没有输入,这点和m-RNN模型是不同的!
单词输入部分还是老思路:和m-RNN模型一样,每个单词采取了独热(one-hot)编码,用来表示单词的是一个维度是词汇表数量的向量。向量和矩阵W_e相乘后,作为输入进入到LSTM中。
使用LSTM来替换了RNN。LSTM是什么东西呢,简单地来说,可以把它看成是效果更好RNN吧。为什么效果更好呢?因为它的公式更复杂哈哈😝(并不是)。


