

欢迎在文章下方评论,建议用电脑看
encoder-decoder模型的想法很简单:对于RNN语言模型,在我们计算输出序列E的概率时,先另一个RNN处理源序列F,来计算语言模型的初始状态。encoder-decoder的含义是:通过第一个神经网络来“编码”F的信息到一个隐层状态,在使用第二个神经网络来预测E“解码”该隐层到输出序列。
模型结构如图
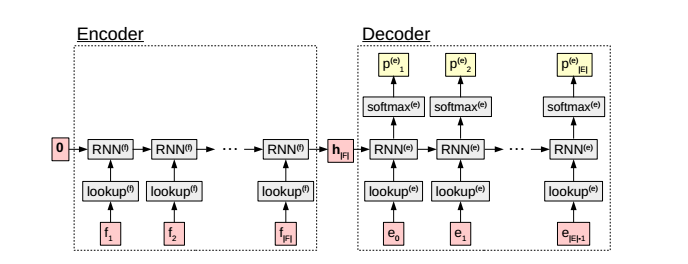
encoder层的处理单元是RNN(f),decoder层是RNN(e),对decoder层的输出采用softmax来获得时刻t输出该隐层的概率,上图的公式为:
mt是输入词序列ft的embedding table;ht是隐层输出,pt是得到的概率。可以看出encoder和decoder的区别在于:encoder的隐层初始值是零,而decoder层的初始值是encoder层的最终输出向量,这意味着decoder层获得了源序列的所有语义信息。
在每次decoder出一个et时,我们将其embedding和输出hidden state连结输入到下一个RNN单元,直到解码到句尾标记。(hidden state经过softmax后得到的概率向量的维度为词典维,类似于one-hot representation,每一维代表词典中的一个词,概率最高即为预测得到的词)
模型的训练目标则是期望这个由Encoder得到的向量能够cover整个句子的语义,从研究人员做的大量实验来看我们发现这样的结构确实可以使得Encoder得到的向量cover整个句子信息。同时Decoder-RNN又能很好的生成一句话。模型cost function为Decoder产生的句子的交叉熵。

在训练的时候,我们需要的是直接用MLE去优化-log值,得到极大似然估计。
在rnn语言模型(rnnlm)中,测试(生成)过程就是利用已经训练好的RNNLM来生成一段文本。具体过程为,首先输入一个初始词用于触发(这个词可以简单的控制生成的内容,比如想生成与“人工智能”相关的内容,那么初始输入就是“人工智能”。倘若想让机器完全自动生成,那么第一个输入就是“start”),然后模型给出一个输出Y1,(这个Yi是词表上所有词的概率分布根据这个概率分布),由这个概率分布,我们通过某种策略(max或者sample策略,后面会详细介绍)选取得到一个词X1,然后再次将X1输入到RNN中,得到Y2,再得到X2,如此往复,至到得到“end”(或者达到最大循环次数)结束生成。
max策略和sample策略。注:这里的sample策略不是很理解的话,可以看下这篇论文Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks其实这两种策略就是如何根据一个概率分布来选择一个词,比如模型在第i个step输出了一个词表上的概率分布Yi,然后我们需要根据这个分布从词表中选择一个词。max策略,顾名思义,就是选择概率值最大的那个词,而sample策略就是根据每个词的概率进行采样。很显然这两种策略的最大区别就是max策略是固定的,也就是第一个词定了之后生成的文本一定是一模一样的,而sample策略则不然,具有一定的随机性,所以即使第一个词固定后每次生成的文本也是不一样的。
max策略的优势就是能够最大化保证句子的通顺,因为选取概率最大的那个词一定是最“通顺”的(概率最大的),但带来的问题就是会出现重复,这个也比较好理解,从生成的整个句子的角度来考虑,max策略会倾向生成概率比较大的句子,而从训练的角度来讲概率大的句子一定是那些出现次数比较多的,因而导致了生成的句子比较固定。对于这一问题的解决方法,就是采用另外一种生成策略——sample策略,这也是karpathy的char-rnn代码中默认的生成策略。sample策略引入一定的随机性,会很有效的避免重复现象的出现,但会牺牲一定的连贯性(通顺度),所以有的人做法是利用sample策略生成一堆候选,然后再训练一个反向RNNLM,利用方向RNNLM和正向RNNLM(用于生成句子的模型)给出的概率值对候选句子进行ranking。
max和sample策略是每一步使用的策略,而beam-search是全局解码算法,其实我们的目的是要得到概率最大的句子,很显然在每一步都取概率最大的词并不能保证最后生成的句子概率是最大的,这个其实是一个图上的最优路径问题,应该是一个动态规划问题而不是一个贪心问题,但是每一步解码时都会有词表大小这么多个节点,想要得到全局最优解搜索空间太大,所以采用beam-search来减少搜索空间,从而得到一个接近最优解的解,为了解决sample策略不连贯的问题,将sample策略和beam-search进行了结合,在每一步解码时用sample得到一些候选,然后选择整体概率高的top-N个结果,就是将我们熟知的beam-search中选最大的N个作为候选的方法改成了按照概率采用N个作为候选。
传统的Encoder-Decoder缺点是,无论之前的context有多长,包含多少信息量,最终都要被压缩成一个几百维的vector。这意味着context越大,最终的state vector会丢失越多的信息。
事实上,因为context在输入时已知,一个模型完全可以在decode的过程中利用context的全部信息,或者部分信息而不仅仅是最后一个state。
而Attention的思想,即在得到Encoder向量后,在进行Decoder的时候模型不仅会用到向量还会用到每个词对应的RNN隐层向量。这里多插入一句,Attention其实是一种思想,它可以有多种实现方式。
attention思想知识一种思想,有多种实现方式,有很多类别,比如soft和hard的区分(这两者的区分主要在于sotf得到attention的上下文Ci是通过加权和得到的,其中的比重最大可以看成是对齐的!而hard的attention的上下文C是固定的一个或者几个的encoder隐状态构成的,用分类表示是否选取莫个隐状态)。
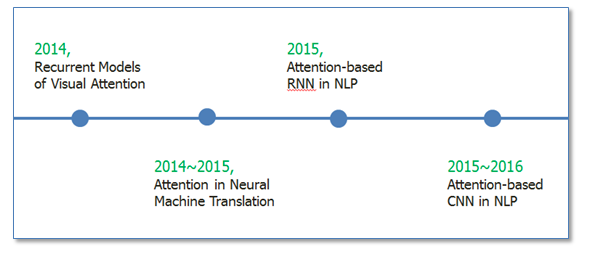
Attention机制最早是在视觉图像领域提出来的,应该是在九几年思想就提出来了,但是真正火起来应该算是google mind团队的这篇论文Recurrent Models of Visual Attention,他们在RNN模型上使用了attention机制来进行图像分类。随后,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》 中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是是第一个提出attention机制应用到NLP领域中。接着类似的基于attention机制的RNN模型扩展开始应用到各种NLP任务中。最近,如何在CNN中使用attention机制也成为了大家的研究热点。下图表示了attention研究进展的大概趋势。
在介绍NLP中的Attention之前,我想大致说一下图像中使用attention的思想。就具代表性的这篇论文Recurrent Models of Visual Attention,他们研究的动机其实也是受到人类注意力机制的启发。人们在进行观察图像的时候,其实并不是一次就把整幅图像的每个位置像素都看过,大多是根据需求将注意力集中到图像的特定部分。而且人类会根据之前观察的图像学习到未来要观察图像注意力应该集中的位置。下图是这篇论文的核心模型示意图。
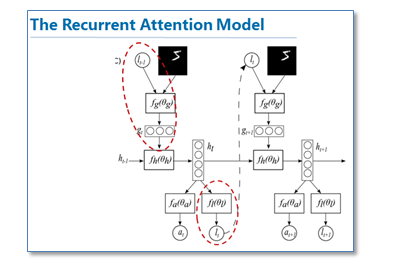
该模型是在传统的RNN上加入了attention机制(即红圈圈出来的部分),通过attention去学习一幅图像要处理的部分,每次当前状态,都会根据前一个状态学习得到的要关注的位置l和当前输入的图像,去处理注意力部分像素,而不是图像的全部像素。这样的好处就是更少的像素需要处理,减少了任务的复杂度。可以看到图像中应用attention和人类的注意力机制是很类似的,接下来我们看看在NLP中使用的attention。
《Neural Machine Translation by Jointly Learning to Align and Translate》
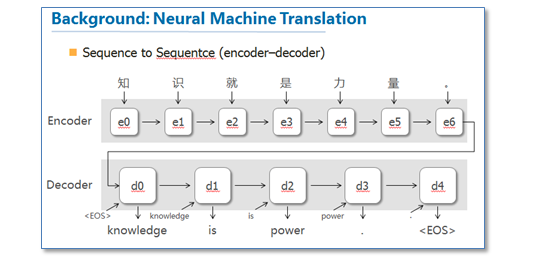
这篇论文算是在NLP中第一个使用attention机制的工作。他们把attention机制用到了神经网络机器翻译(NMT)上,NMT其实就是一个典型的sequence to sequence模型,也就是一个encoder to decoder模型,传统的NMT使用两个RNN,一个RNN对源语言进行编码,将源语言编码到一个固定维度的中间向量,然后在使用一个RNN进行解码翻译到目标语言,传统的模型如下图:
这篇论文提出了基于attention机制的NMT,模型大致如下图:
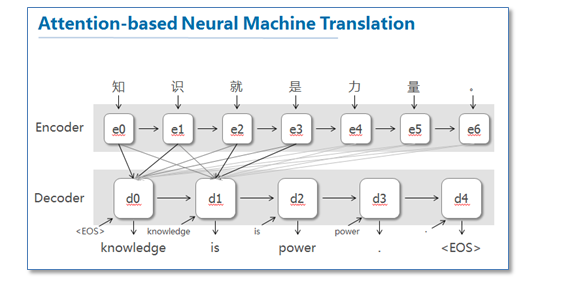
图中我并没有把解码器中的所有连线画玩,只画了前两个词,后面的词其实都一样。可以看到基于attention的NMT在传统的基础上,它把源语言端的每个词学到的表达(传统的只有最后一个词后学到的表达)和当前要预测翻译的词联系了起来,这样的联系就是通过他们设计的attention进行的,在模型训练好后,根据attention矩阵,我们就可以得到源语言和目标语言的对齐矩阵了。具体论文的attention设计部分如下:
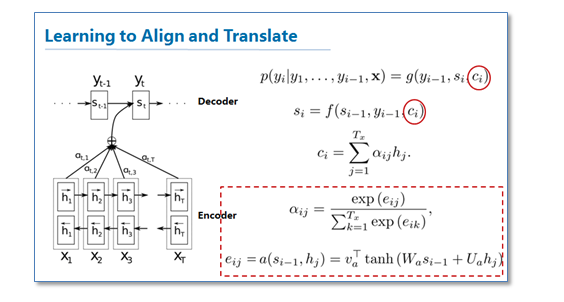
可以看到他们是使用一个感知机公式来将目标语言和源语言的每个词联系了起来,然后通过soft函数将其归一化得到一个概率分布,就是attention矩阵。
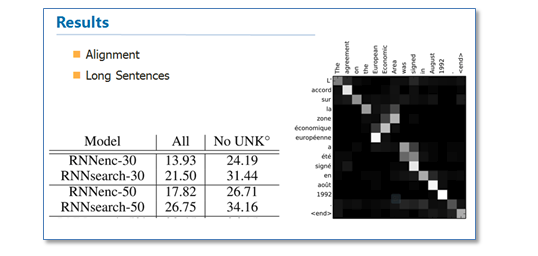
从结果来看相比传统的NMT(RNNsearch是attention NMT,RNNenc是传统NMT)效果提升了不少,最大的特点还在于它可以可视化对齐,并且在长句的处理上更有优势。
在这里的可视化对齐值得是,比如在NMT中,就是两种语言中的单词翻译对应,当然可能顺序是不一样的
这篇论文是继上一篇论文后,一篇很具代表性的论文,他们的工作告诉了大家attention在RNN中可以如何进行扩展,这篇论文对后续各种基于attention的模型在NLP应用起到了很大的促进作用。在论文中他们提出了两种attention机制,一种是全局(global)机制,一种是局部(local)机制。
首先我们来看看global机制的attention,其实这和上一篇论文提出的attention的思路是一样的,它都是对源语言对所有词进行处理,不同的是在计算attention矩阵值的时候,他提出了几种简单的扩展版本。

在他们最后的实验中general的计算方法效果是最好的。
我们再来看一下他们提出的local版本。主要思路是为了减少attention计算时的耗费,作者在计算attention时并不是去考虑源语言端的所有词,而是根据一个预测函数,先预测当前解码时要对齐的源语言端的位置Pt,然后通过上下文窗口,仅考虑窗口内的词。
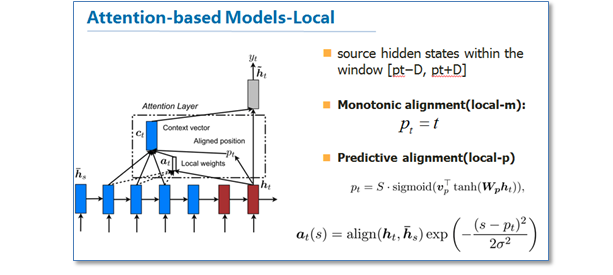
里面给出了两种预测方法,local-m和local-p,再计算最后的attention矩阵时,在原来的基础上去乘了一个pt位置相关的高斯分布。作者的实验结果是局部的比全局的attention效果好。
这篇论文最大的贡献我觉得是首先告诉了我们可以如何扩展attention的计算方式,还有就是局部的attention方法。
随后基于Attention的RNN模型开始在NLP中广泛应用,不仅仅是序列到序列模型,各种分类问题都可以使用这样的模型。那么在深度学习中与RNN同样流行的卷积神经网络CNN是否也可以使用attention机制呢?《ABCNN: Attention-Based Convolutional Neural Network for Modeling Sentence Pairs》 [13]这篇论文就提出了3中在CNN中使用attention的方法,是attention在CNN中较早的探索性工作。
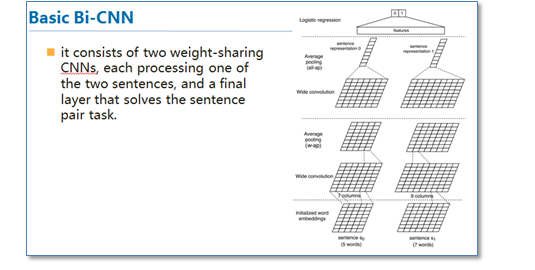
传统的CNN在构建句对模型时如上图,通过每个单通道处理一个句子,然后学习句子表达,最后一起输入到分类器中。这样的模型在输入分类器前句对间是没有相互联系的,作者们就想通过设计attention机制将不同cnn通道的句对联系起来。
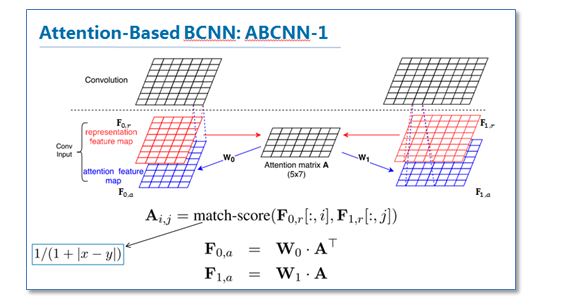
第一种方法ABCNN0-1是在卷积前进行attention,通过attention矩阵计算出相应句对的attention feature map,然后连同原来的feature map一起输入到卷积层。具体的计算方法如下。
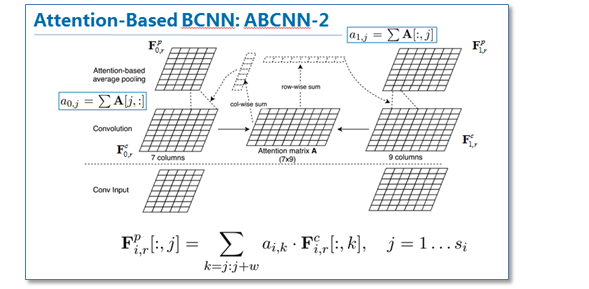
第二种方法ABCNN-2是在池化时进行attention,通过attention对卷积后的表达重新加权,然后再进行池化,原理如下图。
第三种就是把前两种方法一起用到CNN中,如下图
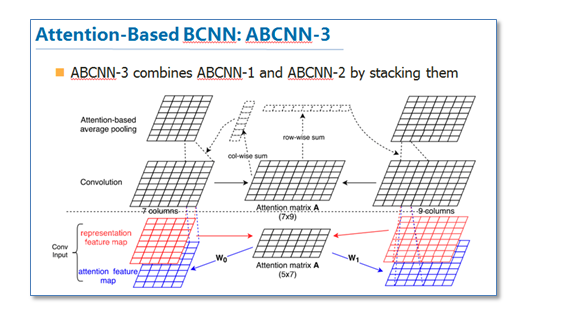
这篇论文提供了我们在CNN中使用attention的思路。现在也有不少使用基于attention的CNN工作,并取得了不错的效果。
最后进行一下总结。Attention在NLP中其实我觉得可以看成是一种自动加权,它可以把两个你想要联系起来的不同模块,通过加权的形式进行联系。目前主流的计算公式有以下几种:

通过设计一个函数将目标模块mt和源模块ms联系起来,然后通过一个soft函数将其归一化得到概率分布。
目前Attention在NLP中已经有广泛的应用。它有一个很大的优点就是可以可视化attention矩阵来告诉大家神经网络在进行任务时关注了哪些部分。
不过在NLP中的attention机制和人类的attention机制还是有所区别,它基本还是需要计算所有要处理的对象,并额外用一个矩阵去存储其权重,其实增加了开销。而不是像人类一样可以忽略不想关注的部分,只去处理关注的部分。
参考博文:
深度学习和自然语言处理中的attention和memory机制
注意力机制(Attention Mechanism)在自然语言处理中的应用


