

欢迎在文章下方评论,建议用电脑看
主要想记录生成序列的gan在nlp的应用。主要是下面两篇论文 SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient Maximum-Likelihood Augmented Discrete Generative Adversarial Networks
GAN最开始是设计用于生成连续数据,但是自然语言处理中我们要用来生成离散tokens的序列。在生成离散tokens的序列时,会产生如下的问题:
1.因为生成器(Generator,简称G)需要利用从判别器(Discriminator,简称D)得到的梯度进行训练,而G和D都需要完全可微,碰到有离散变量的时候## Maximum-Likelihood Augmented Discrete Generative Adversarial Networks(MaliGAN)
这篇论文的主要贡献如下:
1.为G构造一个全新的目标函数,用到了Importance Sampling,将其与D的output结合起来,令训练过程更加稳定同时梯度的方差更低。尽管这个目标函数和RL的方法类似,但是相比之下更能够降低estimator的方差(强烈建议看原文的3.2 Analysis,分析了当D最优以及D经过训练但并没有到最优两种情况下,这个新的目标函数仍然能发挥作用)
2.生成较长序列的时候需要用到多次random sampling,所以文章还提出了两个降低方差的技巧:第一个是蒙特卡罗树搜索,这个大家都比较熟悉; 第二个文章称之为Mixed MLE-Mali Training,就是从真实数据中进行抽样,若序列长度大于N,则固定住前N个词,然后基于前N个词去freely run G产生M个样本,一直run到序列结束。

就会有问题,只用BP不能为G提供训练的梯度。在GAN中我们通过对G的参数进行微小的改变,令其生成的数据更加“逼真”。若生成的数据是基于离散的tokens,D给出的信息很多时候都没有意义,因为和图像不同。图像是连续的,微小的改变可以在像素点上面反应出来,但是你对tokens做微小的改变,在对应的dictionary space里面可能根本就没有相应的tokens.
2.GAN只可以对已经生成的完整序列进行打分,而对一部分生成的序列,如何判断它现在生成的一部分的质量和之后生成整个序列的质量也是一个问题。
在这篇论文中,针对上面第一个问题,首先是将D的输出作为Reward,然后用Policy Gradient Method来训练G,也就是用D的输出作为Reward作为指导来改变Policy Gradient的方向,这也符合对抗网络的思想。针对第二个问题,通过蒙特卡罗搜索,针对部分生成的序列,用一个Roll-Out Policy(也是一个LSTM)来Sampling完整的序列,再交给D打分,最后对得到的Reward求平均值。
之前his is due to the generator network in GAN is designed to be able to adjust the output continuously, which does not work on discrete data generation,也就是说作者说它不适合做text生成。
详细请看redditGenerative adversarial networks for text.
The most popular way of training RNNs is to maximize the likelihood of each token in the training data whereas (Bengio et al. 2015) pointed out that the discrepancy between training and generating makes the maximum likelihood estimation suboptimal and proposed scheduled sampling strategy (SS). Later(Huszár 2015) theorized that the objective function underneath SS is improper and explained the reason why GANs tend to generate natural looking samples in theory. Consequently, the GANs have great potential but are not practically feasible to discrete probabilistic models currently.
上面的一段话摘自ralated work,这里说明了RNN的bias exposure的问题和在How (not) to train your generative model: Scheduled sampling, likelihood, adversary说明了之前ss策略的不合理性和GAN的generate natural-looking samples。也就是说GAN存在潜力,只是在现实中没有表现。
在这篇文章中提到Data generation as sequential decision making,序列可以表示成为一个a sequential decision making process, which can be potentially be solved by reinforcement learning techniques. 也就是这种问题可以由RL的方式来解决,当然,事实也是如此。现在很多的论文也是通过rl的方式来解决。
受到阿尔法狗的启发,因为reward都是对整体的,所以同样的应用了蒙特卡洛搜索,引用的是这个:A survey of monte carlo tree search methods。
MLE:
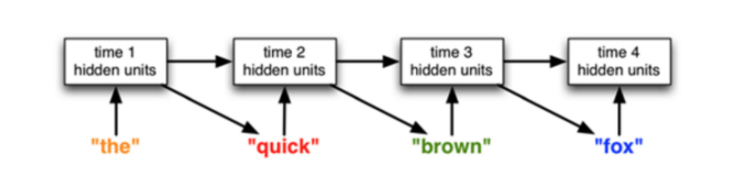
传统的LSTM generator模型,其实就是语言模型。
DAD(一种MLE的改进模型)
Scheduled sampling for sequence prediction with recurrent neural networks.
改进MLE的训练过程,解决生成模型decode阶段的exposure bias问题,即在训练过程中逐渐用预测输出替代实际输出作为下一个词的输入。
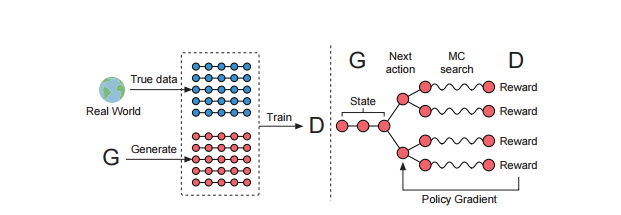
1。左图为GAN网络训练的步骤1,即根据真实样本和伪造样本训练判别器D网 络,这里的D网络用的CNN实现。
用到的判别器(Discriminator)是卷积神经网络(CNN),而不是递归神经网络(RNN),这可能是一个不错的选择,因为Tong Zhang 就曾经使用CNN 做文本分类任务,相比 RNN,CNN 更好训练一些,最终训练得到的判别器非常有效,与之相关的问题优化起来也相对容易些。
2、右图为GAN网络训练的步骤2,根据D网络回传的判别概率通过增强学习更新G网络,这里的G网络用的LSTM实现。
3、已知G网络的更新策略是增强学习,而增强学习的三个要素点状态state,action,reward。
本文state指的当前timestep之前的decode结果,也就是lstm随机生成的t个词,action指的当前待解码词,也就是第t个词,D网络判别伪造数据的置信度即为奖励,伪造数据越逼真则相应奖励越大,但该奖励是总的奖励,分配到每个词选择上的reward则采用了以下的近似方法。
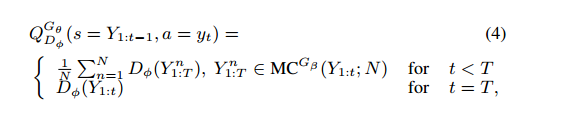
简单解释,即当解码到t时,即对后面T-t个timestep采用蒙特卡洛搜索搜索出N条路径,将这N条路径分别和已经decode的结果组成N条完整输出,然后将D网络对应奖励的平均值作为reward.因为当t=T时无法再向后探索路径,所以直接以完整decode结果的奖励作为reward。蒙特卡洛搜索是指在选择下一个节点的时候用蒙特卡洛采样的方式,而蒙特卡洛采样是指根据当前输出词表的置信度随机采样。
算法结构如下:

通过G网络生成sequence用D网络去评判,得到reward。
根据(4)计算得到每个action选择得到的奖励并求得累积奖励的期望,以此为loss function,并求导对网络进行梯度更新。
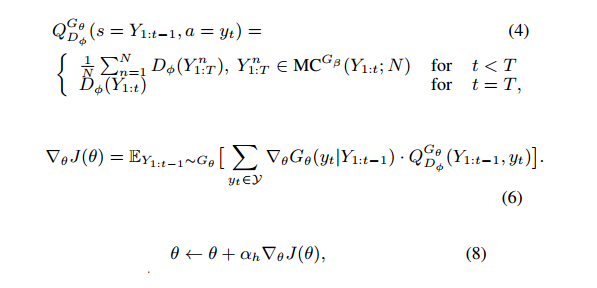
5、以下是标准的D网络误差函数,训练目标是最大化识别真实样本的概率,最小化误识别伪造样本的概率。
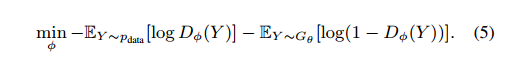
最后还像提一下的是,后来的Adversarial Learning for Neural Dialogue Generation用了Policy Gradient Method来对GAN进行训练,和SeqGAN的方法并没有很大的区别,主要是用在了Dialogue Generation这样困难的任务上面。还有两点就是:第一点是除了用蒙特卡罗搜索来解决部分生成序列的问题之外,因为MC Search比较耗费时间,还可以训练一个特殊的D去给部分生成的序列进行打分(这里其实应该是联想到actor critic的做法)。但是从实验效果来看,MC Search的表现要更好一点。
最后说下在论文中的rollout policy 是什么?取自AlphaGo’s paper中
The rollout policy … is a linear softmax policy based on fast, incrementally computed, local pattern-based features …
也可以参看这个回答
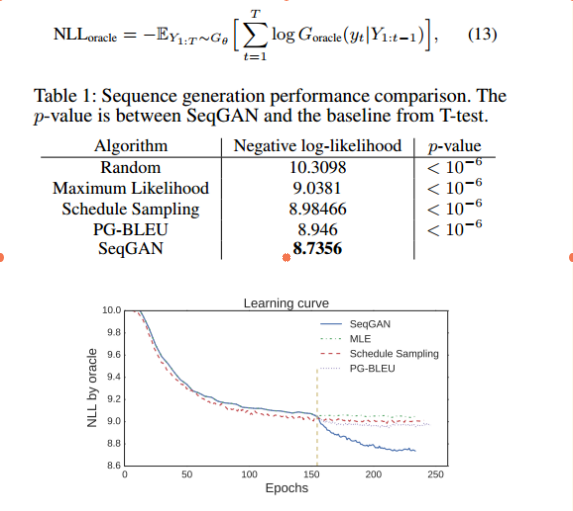
随机初始一个lstm生成器A,随机生成一部分训练数据,来训练各种生成模型,最后让各种生成模型随机产生一批验证数据,用生成器A去校验这些验证数据是否符合自己的分布。具体方式就是假设验证数据是a,b,c,。将a输入A查看输出b的概率p(b/a),再输入c查看p(c/a,b)然后用以下标准评判。评判标准:负对数似然也就是交叉熵。


