

欢迎在文章下方评论,建议用电脑看
这个关于MCTS的ppt值得一看
基本的 MCTS 算法非常简单:根据模拟的输出结果,按照节点构造搜索树。其过程可以分为下面的若干步:
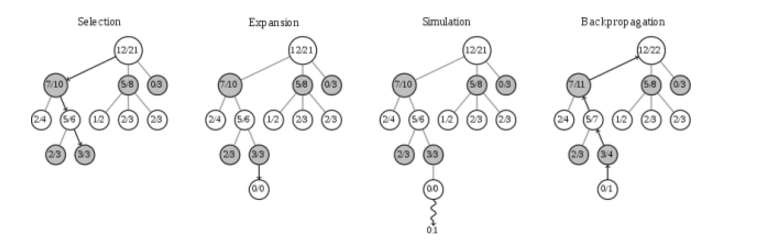
1.选择 Selection:从根节点 R 开始,递归选择最优的子节点(后面会解释)直到达到叶子节点 L。
2.扩展 Expansion:如果 L 不是一个终止节点(也就是,不会导致博弈游戏终止)那么就创建一个或者更多的字子节点,选择其中一个 C。
3.模拟 Simulation:从 C 开始运行一个模拟的输出,直到博弈游戏结束。
4.反向传播 Backpropagation:用模拟的结果输出更新当前行动序列。
每个节点并需包含两个重要的信息:一个是根据模拟结果估计的值和该节点已经被访问的次数。
按照最为简单和最节约内存的实现,MCTS 将在每个迭代过程中增加一个子节点。不过,要注意其实根据不同的应用这里也可以在每个迭代过程中增加超过一个子节点。
在树向下遍历时的节点选择通过选择最大化某个量来实现,这其实类似于 Multiarmed bandit problem,其中的参与者必须选择一个 slot machine(bandit)来最大化每一轮的估计的收益。我们可以使用 Upper Confidence Bounds(UCB)公式常常被用来计算这个:
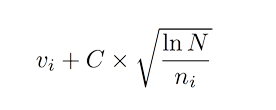
其中 v_i 是节点估计的值,n_i 是节点被访问的次数,而 N 则是其父节点已经被访问的总次数。C 是可调整参数。
可能一开始看得时候有点不能理解,这个时候可以看下一个具体的例子,就是放在棋类中是怎么样运行的或者用老虎机作为解释来理解MCTS中的UCB
UCB 公式对已知收益的 exploitation 和鼓励接触那些相对未曾访问的节点的 exploration 进行平衡。收益估计基于随机模拟,所以节点必须被访问若干次来缺包估计变得更加可信;MCTS 估计会在搜索的开始不大可靠,而最终会在给定充分的时间后收敛到更加可靠的估计上,在无限时间下能够达到最优估计。
Kocsis 和 Szepervari 在 2006 年首先构建了一个完备的 MCTS 算法,通过扩展 UCB 到 树搜索,并将其命名为 Upper Confidence Bounds for Trees(UCT)方法。这其实是用在当前众多 MCTS 实现中的算法版本。
UCT 可以被描述为 MCTS 的一个特例:UCT = MCTS + UCB。也即是说UCB在树方面的应用。
MCTS 不要求任何关于给定的领域策略或者具体实践知识来做出合理的决策。这个算法可以在没有任何关于博弈游戏除基本规则外的知识的情况下进行有效工作;这意味着一个简单的 MCTS 实现可以重用在很多的博弈游戏中,只需要进行微小的调整,所以这也使得 MCTS 是对于一般的博弈游戏的很好的方法。
MCTS 执行一种非对称的树的适应搜索空间拓扑结构的增长。这个算法会更频繁地访问更加有趣的节点,并聚焦其搜索时间在更加相关的树的部分。
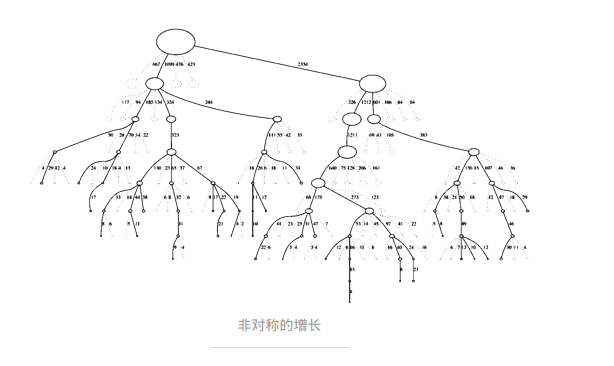
这使得 MCTS 更加适合那些有着更大的分支因子的博弈游戏,比如说 19X19 的围棋。这么大的组合空间会给标准的基于深度或者宽度的搜索方法带来问题,所以 MCTS 的适应性说明它(最终)可以找到那些更加优化的行动,并将搜索的工作聚焦在这些部分。
MCTS 有很少的缺点,不过这些缺点也可能是非常关键的影响因素。
MCTS 算法,根据其基本形式,在某些甚至不是很大的博弈游戏中在可承受的时间内也不能够找到最好的行动方式。这基本上是由于组合步的空间的全部大小所致,关键节点并不能够访问足够多的次数来给出合理的估计。
MCTS 搜索可能需要足够多的迭代才能收敛到一个很好的解上,这也是更加一般的难以优化的应用上的问题。例如,最佳的围棋程序可能需要百万次的交战和领域最佳和强化才能得到专家级的行动方案,而最有的 GGP 实现对更加复杂的博弈游戏可能也就只要每秒钟数十次(领域无关的)交战。对可承受的行动时间,这样的 GGP 可能很少有时间访问到每个合理的行动,所以这样的情形也不大可能出现表现非常好的搜索。
幸运的是,算法的性能可以通过一些技术显著提升。
很多种 MCTS 强化的技术已经出现了。这些基本上可以归纳为领域知识或者领域独立两大类。
特定博弈游戏的领域知识可以用在树上来过滤掉不合理的行动或者在模拟过程中产生重要的对局(更接近人类对手的表现)。这意味着交战结果将会更加的现实而不是随机的模拟,所以节点只需要少量的迭代就能给出一个现实的收益值。
领域知识可以产生巨大的性能提升,但在速度和一般性上也会有一定的损失。
领域独立强化能够应用到所有的问题领域中。这些一般用在树种(如 AMAF),还有一些用在模拟(如 在交战时倾向于胜利的行动)。领域独立强化并不和特定的领域绑定,具有一般性,这也是当前研究的重心所在。


