

欢迎在文章下方评论,建议用电脑看
强化学习中的一种结合体 Actor Critic (演员评判家), 它合并了 以值为基础 (比如 Q learning) 和 以动作概率为基础 (比如 Policy Gradients) 两类强化学习算法.
我们有了像 Q-learning 这么伟大的算法, 为什么还要瞎折腾出一个 Actor-Critic? 原来 Actor-Critic 的 Actor 的前生是 Policy Gradients,或者说其实这也是一种Policy Gradients, 这能让它毫不费力地在连续动作中选取合适的动作, 而 Q-learning 做这件事会瘫痪. 那为什么不直接用 Policy Gradients 呢? 原来 Actor Critic 中的 Critic 的前生是 Q-learning 或者其他的 以值为基础的学习法 , 能进行单步更新, 而传统的 Policy Gradients 则是回合更新, 这降低了学习效率.也就是说Actor Critic比单纯的Policy Gradients的效率要高。
接着上次Policy Gradients,那里引入一个baseline。

这里需要注意的就是其实在我的理解下:actor加上策略的Prediction就是actor-critic模型。而这个prediction在Q-learning那里就是少了greedy or e-greedy(这个在之前已知。只不过这里需要注意的就是on-learning和off-learning的区别)

训练actor常用的是policy gradient,训练critic可以用蒙特卡洛或者temporal difference(TD),训练一定要用experience replay。
现在我们有两套不同的体系, Actor 和 Critic, 他们都能用不同的神经网络来代替 . 在 Policy Gradients 的影片中提到过, 现实中的奖惩会左右 Actor 的更新情况. Policy Gradients 也是靠着这个来获取适宜的更新. 那么何时会有奖惩这种信息能不能被学习呢? 这看起来不就是 以值为基础的强化学习方法做过的事吗. 那我们就拿一个 Critic 去学习这些奖惩机制, 学习完了以后. 由 Actor 来指手画脚, 由 Critic 来告诉 Actor 你的那些指手画脚哪些指得好, 哪些指得差, Critic 通过学习环境和奖励之间的关系, 能看到现在所处状态的潜在奖励, 所以用它来指点 Actor 便能使 Actor 每一步都在更新, 如果使用单纯的 Policy Gradients, Actor 只能等到回合结束才能开始更新,这也是效率低的原因.
结合了 Policy Gradient (Actor) 和 Function Approximation (Critic) 的方法. Actor 基于概率选行为, Critic 基于 Actor 的行为评判行为的得分, Actor 根据 Critic 的评分修改选行为的概率.
结合到具体的网络上就是:Actor和Critic各为一个网络,Actor输入是状态输出的是动作,loss就是
log_prob*td_error,(注意到这里的loss和Policy Gradient中的差不多,知识vt换成td_error,引导奖励值vt换了来源而已),Critic输入的是状态输出的是V值(注意这里不是Q值),loss是square((r+gamma*V_next) - V_eval)也就是square(td_error)。他们两个网络交互更新是这样的:agent每次状态s1从actor中选择一个动作a1(也就是从actor网络的获得的动作)执行得到s2,和立即奖励r。然后把s1,s2,r喂给Critic网络更新参数并得到td_error,然后将a1,s1,td_error喂给actor网络更新参数,需要注意的是两个网络是同时更新的
下面是基础Actor Critic的示意图,这个图比较好的说明了基础Actor Critic是如何运作的。
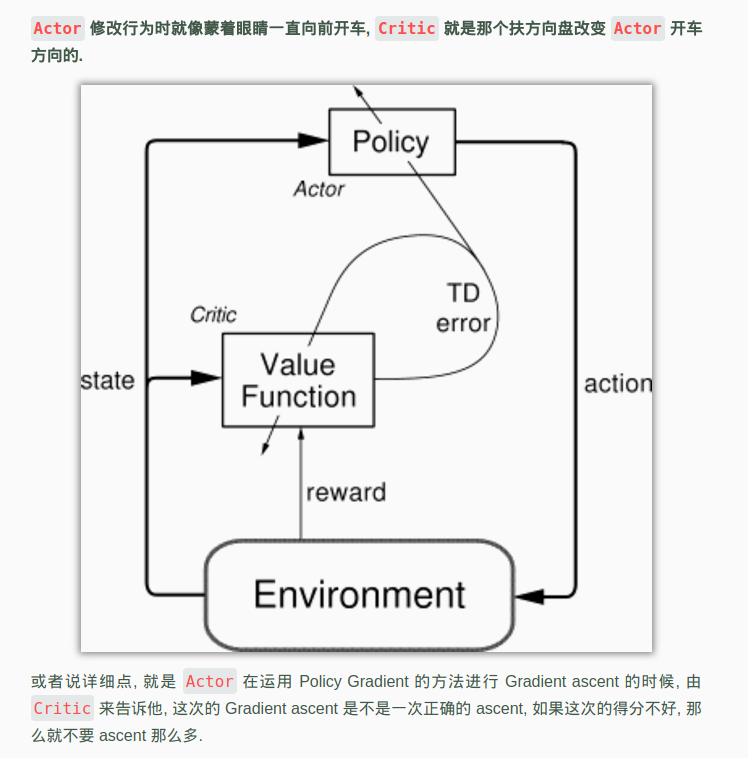
注:这里首先讲的是最基础的Actor Critic,它由两个网络构成
基础Actor Critic涉及到了两个神经网络, 而且每次都是在连续状态中更新参数, 每次参数更新前后都存在相关性, 导致神经网络只能片面的看待问题, 甚至导致神经网络学不到东西. Google DeepMind 为了解决这个问题, 修改了 Actor Critic 的算法,
一句话概括 DDPG: Google DeepMind 提出的一种使用 Actor Critic 结构, 但是输出的不是行为的概率, 而是具体的行为, 用于连续动作 (continuous action) 的预测. DDPG 结合了之前获得成功的 DQN 结构, 提高了 Actor Critic 的稳定性和收敛性.,DDPG 最大的优势就是能够在连续动作上更有效地学习,当然还有就是解决了之前基础Actor Critic难以收敛的问题。

因为 DDPG 和 DQN 还有 Actor Critic 很相关, 所以最好这两者都了解下, 对于学习 DDPG 很有帮助, Actor critic 让 Policy gradient 单步更新的精华, 而且还吸收让计算机学会玩游戏的 DQN 的精华.
网络有四个,其实大体上和基础 Actor Critic差不多,都是Actor给动作给Critic进行评估,Critic给反馈(基础中是td_error,而这里是dQ/da)给Actor进行更新参数。


