

欢迎在文章下方评论,建议用电脑看
目前面临的基本问题是:所有的理论都认为 GAN 应该在纳什均衡(Nash equilibrium)上有卓越的表现,但梯度下降只有在凸函数的情况下才能保证实现纳什均衡。当博弈双方都由神经网络表示时,在没有实际达到均衡的情况下,让它们永远保持对自己策略的调整是可能的【OpenAI Ian Goodfellow的Quora】。
GAN模型被定义为极小极大问题,没有损失函数,在训练过程中很难区分是否正在取得进展。GAN的学习过程可能发生崩溃问题(collapse problem),生成器开始退化,总是生成同样的样本点,无法继续学习。当生成模型崩溃时,判别模型也会对相似的样本点指向相似的方向,训练无法继续。【Improved Techniques for Training GANs】
与其他生成式模型相比,GAN这种竞争的方式不再要求一个假设的数据分布,即不需要formulate p(x),而是使用一种分布直接进行采样sampling,从而真正达到理论上可以完全逼近真实数据,这也是GAN最大的优势。然而,这种不需要预先建模的方法缺点是太过自由了,对于较大的图片,较多的 pixel的情形,基于简单 GAN 的方式就不太可控了。在GAN[Goodfellow Ian, Pouget-Abadie J] 中,每次学习参数的更新过程,被设为D更新k回,G才更新1回,也是出于类似的考虑。
生成器在生成数据和人脸时效果很好,但使用CIFAR-10数据集时,生成的图像就十分模糊。
做到了以下爆炸性的几点:

一句话概括:判别器越好,生成器梯度消失越严重


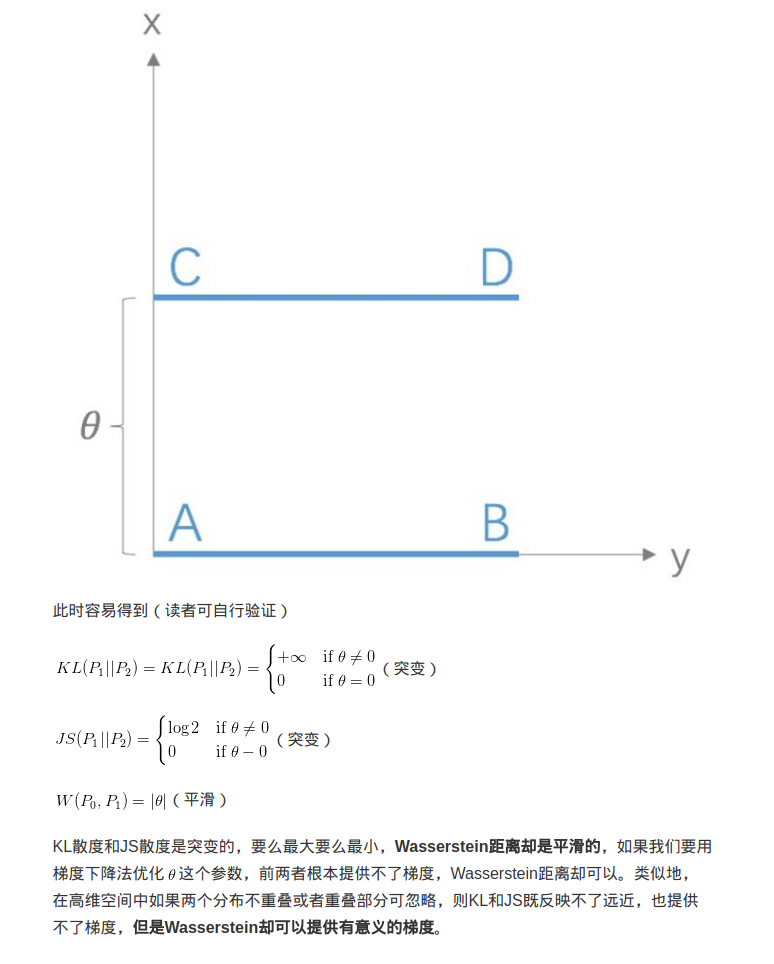
根据原始GAN定义的判别器loss,我们可以得到最优判别器的形式;而在最优判别器的下,我们可以把原始GAN定义的生成器loss等价变换为最小化真实分布P_r与生成分布P_g之间的JS散度。我们越训练判别器,它就越接近最优,最小化生成器的loss也就会越近似于最小化P_r和P_g之间的JS散度。
问题就出在这个JS散度上。我们会希望如果两个分布之间越接近它们的JS散度越小,我们通过优化JS散度就能将P_g“拉向”P_r,最终以假乱真。这个希望在两个分布有所重叠的时候是成立的,但是如果两个分布完全没有重叠的部分,或者它们重叠的部分可忽略(下面解释什么叫可忽略),JS散度就固定是常数log 2,而这对于梯度下降方法意味着——梯度为0!
而且:P_r与P_g不重叠或重叠部分可忽略的可能性非常大 下面解释专业解释:
当P_r与P_g的支撑集(support)是高维空间中的低维流形(manifold)时,P_r与P_g重叠部分测度(measure)为0的概率为1。
不用被奇怪的术语吓得关掉页面,虽然论文给出的是严格的数学表述,但是直观上其实很容易理解。首先简单介绍一下这几个概念:
支撑集(support)其实就是函数的非零部分子集,比如ReLU函数的支撑集就是(0, +oo),一个概率分布的支撑集就是所有概率密度非零部分的集合。
流形(manifold):是高维空间中曲线、曲面概念的拓广,我们可以在低维上直观理解这个概念,比如我们说三维空间中的一个曲面是一个二维流形,因为它的本质维度(intrinsic dimension)只有2,一个点在这个二维流形上移动只有两个方向的自由度。同理,三维空间或者二维空间中的一条曲线都是一个一维流形。
测度(measure)是高维空间中长度、面积、体积概念的拓广,可以理解为“超体积”。
回过头来看第一句话,“当P_r与P_g的支撑集是高维空间中的低维流形时”,基本上是成立的。原因是GAN中的生成器一般是从某个低维(比如100维)的随机分布中采样出一个编码向量,再经过一个神经网络生成出一个高维样本(比如64x64的图片就有4096维)。当生成器的参数固定时,生成样本的概率分布虽然是定义在4096维的空间上,但它本身所有可能产生的变化已经被那个100维的随机分布限定了,其本质维度就是100,再考虑到神经网络带来的映射降维,最终可能比100还小,所以生成样本分布的支撑集就在4096维空间中构成一个最多100维的低维流形,“撑不满”整个高维空间。
“撑不满”就会导致真实分布与生成分布难以“碰到面”,这很容易在二维空间中理解:一方面,二维平面中随机取两条曲线,它们之间刚好存在重叠线段的概率为0;另一方面,虽然它们很大可能会存在交叉点,但是相比于两条曲线而言,交叉点比曲线低一个维度,长度(测度)为0,可忽略。三维空间中也是类似的,随机取两个曲面,它们之间最多就是比较有可能存在交叉线,但是交叉线比曲面低一个维度,面积(测度)是0,可忽略。从低维空间拓展到高维空间,就有了如下逻辑:因为一开始生成器随机初始化,所以P_g几乎不可能与P_r有什么关联,所以它们的支撑集之间的重叠部分要么不存在,要么就比P_r和P_g的最小维度还要低至少一个维度,故而测度为0。所谓“重叠部分测度为0”,就是上文所言“不重叠或者重叠部分可忽略”的意思。
最小化第二种生成器loss函数,会等价于最小化一个不合理的距离衡量,导致两个问题,一是梯度不稳定,二是collapse mode即多样性不足。

| 换言之,KL(P_g | P_r)对于上面两种错误的惩罚是不一样的,第一种错误对应的是“生成器没能生成真实的样本”,惩罚微小;第二种错误对应的是“生成器生成了不真实的样本” ,惩罚巨大。第一种错误对应的是缺乏多样性,第二种错误对应的是缺乏准确性。在这里,我们可以想象一下,gan是一个智能的,他在这一放一打之下,生成器宁可多生成一些重复但是很“安全”的样本,也不愿意去生成多样性的样本,因为那样一不小心就会产生第二种错误,得不偿失。这种现象就是大家常说的collapse mode。 |



Wesserstein GAN的算法如下:

前三点都是从理论分析中得到的,已经介绍完毕;第四点却是作者从实验中发现的,属于trick,相对比较“玄”。作者发现如果使用Adam,判别器的loss有时候会崩掉,当它崩掉时,Adam给出的更新方向与梯度方向夹角的cos值就变成负数,更新方向与梯度方向南辕北辙,这意味着判别器的loss梯度是不稳定的,所以不适合用Adam这类基于动量的优化算法。作者改用RMSProp之后,问题就解决了,因为RMSProp适合梯度不稳定的情况。
最后,对于w-gan的最新进展,就是采用gradient penalty对Lipschitz限制,效果更好,更加稳定,在知乎上有比较好的中文讲解,非常值得一看。


