欢迎在文章下方评论,建议用电脑看
上次课谈到了在给定policy的情况下求解未知environment的MDP问题,称之为Model-Free Prediction问题。本节则是解决未知policy情况下未知environment的MDP问题,也就是Model-Free Control问题,这个问题实际上是最常见的强化学习问题。由于这种问题中未知policy,那么就有两种思路来获得policy,一种称为on-policy learning是基于某个policy做出一些action然后评估这个policy效果如何,一种称为off-policy learning是从一些已知的policy中学习policy,比如机器人在学习走路时,可以从人控制机器人走路的sample中来学习,但不是完全的跟sample走的action完全一样,在sample中尝试去走不同的一步看是否有更好reward。
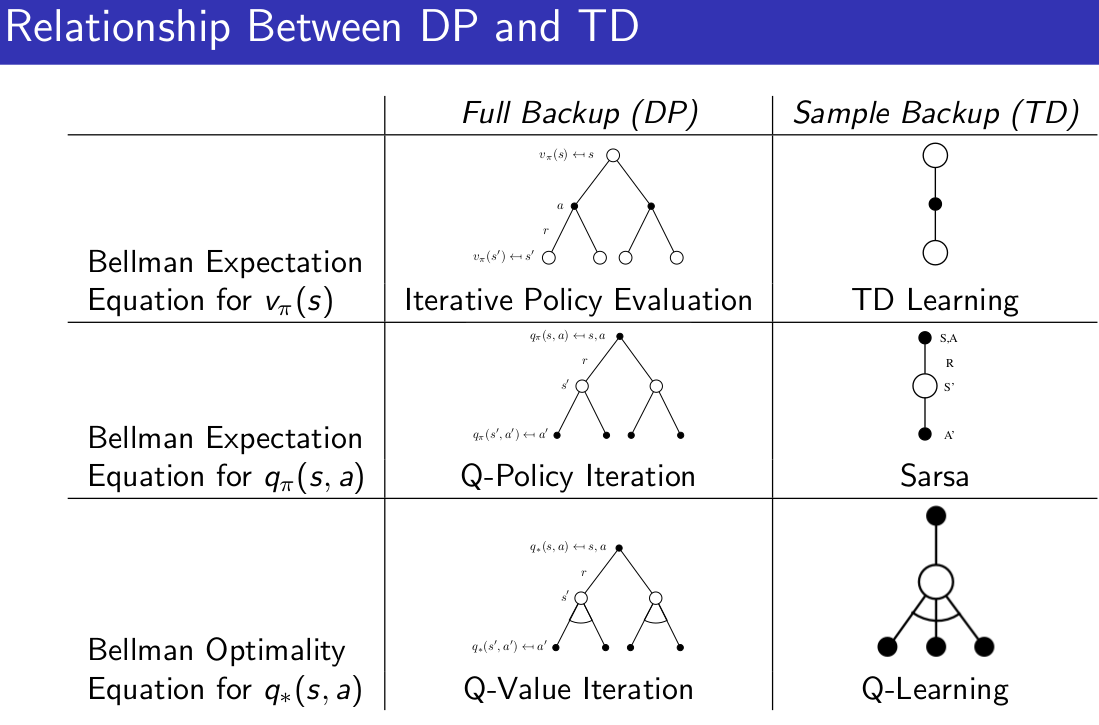
On-Policy Monte-Carlo由policy evaluation + ϵ−Greedy Policy Improvement组成。
在第三课的动态规划解决planning问题(已知environment)中提出的Policy iteration和value iteration,其中policy iteration由policy evaluation和policy improvement组成。第四课中未知environment的policy evaluation是通过蒙特卡洛方法求解,结合起来到本课可以得到第一个解决Model-Free control方法即先通过贪婪算法来确定当前的policy,再通过蒙特卡洛policy evaluation来评估当前的policy好不好,再更新policy。
如果在已知environment情况下policy improvement更新方式是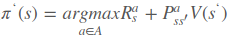 ,可以看出它的解决方案是通过状态转移矩阵把所有可能转移到的状态得到的值函数都计算出来,从中来选择最大的,但未知environment则没有状态转移矩阵,因此只能通过最大化动作值函数来更新policy即
,可以看出它的解决方案是通过状态转移矩阵把所有可能转移到的状态得到的值函数都计算出来,从中来选择最大的,但未知environment则没有状态转移矩阵,因此只能通过最大化动作值函数来更新policy即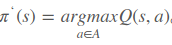 。由于improvement的过程需要动作值函数,那么在policy evaluation的过程中针对给定的policy需要计算的V(s)也替换成Q(s,a)。
。由于improvement的过程需要动作值函数,那么在policy evaluation的过程中针对给定的policy需要计算的V(s)也替换成Q(s,a)。
但是greedy算法是存在一定的问题的,例如现在有两扇门,打开一扇门会有一定的奖励,经过一些开门试验后选择能够获得奖励最大的门。假设第一次打开左边的门获得的immdiate reward是0,那么左边门的return更新为V(left)=0V(left)=0,第二次打开右边获得的immdiate reward是+1,右边门return更新V(right)=1V(right)=1,此时如果根据greedy算法,那么下一次肯定会选择右边的门,第三次选择右边门获得reward是+3,return更新为V(right)=2V(right)=2(蒙特卡洛方法平均了一下),根据greedy算法第四次也会选择右边门。因此按照贪婪算法就会一直选择右边门,但是其实我们并不清楚左边门到底是什么情况,我们只尝试了一次。从这个例子可以看出,需要对执行每个action的结果都做比较充分的了解,才能说自己的policy是正确的。
因此提出改进算法在greedy基础上有一定概率选择一个随机action,即ϵ−Greedy Exploration,假设有m个action,那么有ϵϵ的概率随机选择一个action(包括greedy action),从而可以得到更新的policy为(17:48开始证明了改进算法算出的新policy比之前的好,此处略过)
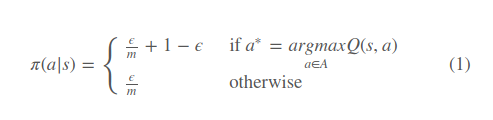
如果每一个的episode都进行一次evaluation和improvement迭代,那么在第k次迭代时可以更新ϵ=1kϵ=1k。更新ϵϵ的算法称之为GLIE Monte-Carlo Control。



Q-Learning 整体算法:


从算法来看, 这就是他们两最大的不同之处了. 因为 Sarsa 是说到做到型, 所以我们也叫他 on-policy, 在线学习, 学着自己在做的事情. 而 Q learning 是说到但并不一定做到, 所以它也叫作 Off-policy, 离线学习. 而因为有了 maxQ, Q-learning 也是一个特别勇敢的算法.
其实也就是在Q现实的选取上有所不同,Q-Learning的Q现实是借助别人的好的经验或者之前一段时间的经验(这样的经验是比较稳的)而Sarsa的Q现实是即时的选取,是一种比较激进的的做法。
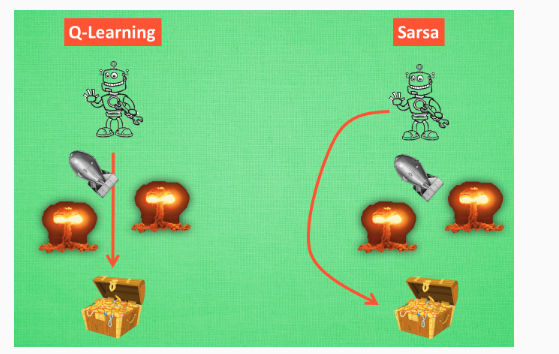
为什么说他勇敢呢, 因为 Q learning 机器人 永远都会选择最近的一条通往成功的道路, 不管这条路会有多危险. 而 Sarsa 则是相当保守, 他会选择离危险远远的, 拿到宝藏是次要的, 保住自己的小命才是王道. 这就是使用 Sarsa 方法的不同之处.