

欢迎在文章下方评论,建议用电脑看
我们将要实现一种更强大的方法来解决图像分类问题,该方法可以自然地延伸到神经网络和卷积神经网络上。这种方法主要有两部分组成:一个是评分函数(score function),它是原始图像数据到类别分值的映射。另一个是损失函数(loss function),它是用来量化预测分类标签的得分与真实标签之间一致性的。该方法可转化为一个最优化问题,在最优化过程中,将通过更新评分函数的参数来最小化损失函数值。
线性分类器计算图像中3个颜色通道中所有像素的值与权重的矩阵乘,从而得到分类分值。根据我们对权重设置的值,对于图像中的某些位置的某些颜色,函数表现出喜好或者厌恶(根据每个权重的符号而定)。举个例子,可以想象“船”分类就是被大量的蓝色所包围(对应的就是水)。那么“船”分类器在蓝色通道上的权重就有很多的正权重(它们的出现提高了“船”分类的分值),而在绿色和红色通道上的权重为负的就比较多(它们的出现降低了“船”分类的分值)。
————————————————————————————————————————
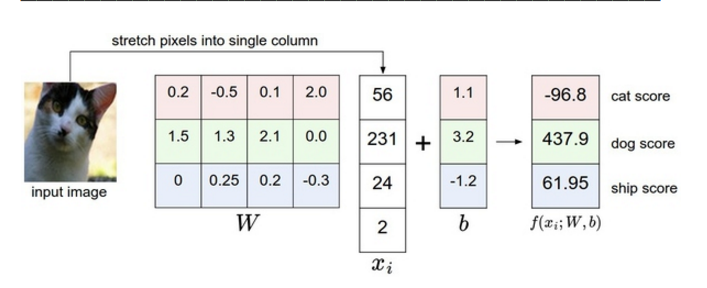
一个将图像映射到分类分值的例子。为了便于可视化,假设图像只有4个像素(都是黑白像素,这里不考虑RGB通道),有3个分类(红色代表猫,绿色代表狗,蓝色代表船,注意,这里的红、绿和蓝3种颜色仅代表分类,和RGB通道没有关系)。首先将图像像素拉伸为一个列向量,与W进行矩阵乘,然后得到各个分类的分值。需要注意的是,这个W一点也不好:猫分类的分值非常低。从上图来看,算法倒是觉得这个图像是一只狗。
将图像看做高维度的点:既然图像被伸展成为了一个高维度的列向量,那么我们可以把图像看做这个高维度空间中的一个点(即每张图像是3072维空间中的一个点)。整个数据集就是一个点的集合,每个点都带有1个分类标签。
损失函数的具体形式多种多样。首先,介绍常用的多类支持向量机(SVM)损失函数。SVM的损失函数想要SVM在正确分类上的得分始终比不正确分类上的得分高出一个边界值\Delta。我们可以把损失函数想象成一个人,这位SVM先生(或者女士)对于结果有自己的品位,如果某个结果能使得损失值更低,那么SVM就更加喜欢它。



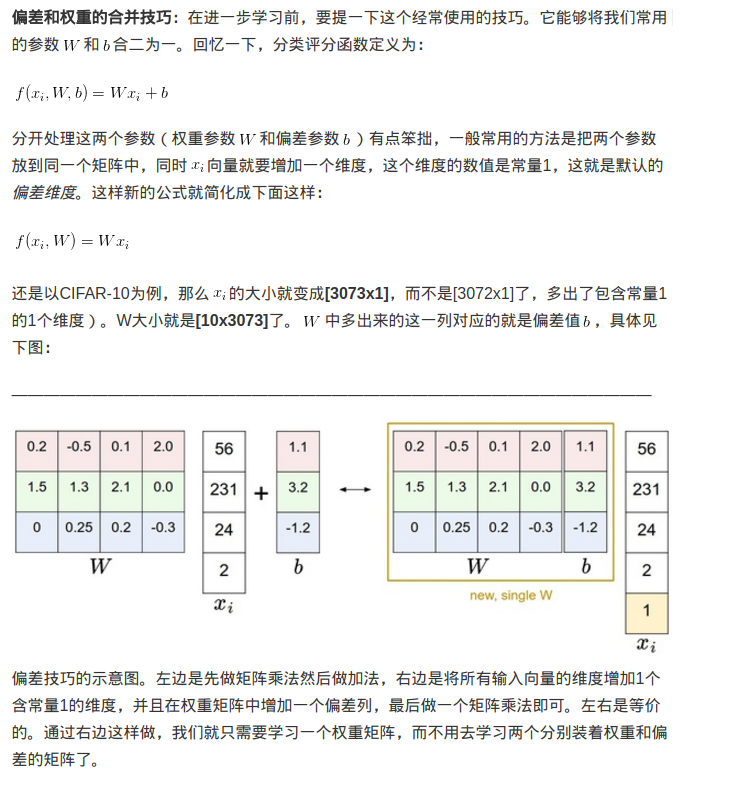
需要注意的是,和权重不同,偏差没有这样的效果,因为它们并不控制输入维度上的影响强度。因此通常只对权重W正则化,而不正则化偏差b。在实际操作中,可发现这一操作的影响可忽略不计。最后,因为正则化惩罚的存在,不可能在所有的例子中得到0的损失值,这是因为只有当W=0的特殊情况下,才能得到损失值为0。



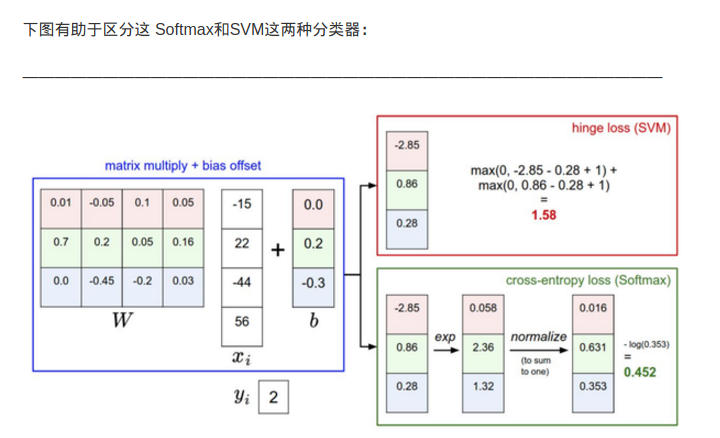
针对一个数据点,SVM和Softmax分类器的不同处理方式的例子。两个分类器都计算了同样的分值向量f(本节中是通过矩阵乘来实现)。不同之处在于对f中分值的解释:SVM分类器将它们看做是分类评分,它的损失函数鼓励正确的分类(本例中是蓝色的类别2)的分值比其他分类的分值高出至少一个边界值。Softmax分类器将这些数值看做是每个分类没有归一化的对数概率,鼓励正确分类的归一化的对数概率变高,其余的变低。SVM的最终的损失值是1.58,Softmax的最终的损失值是0.452,但要注意这两个数值没有可比性。只在给定同样数据,在同样的分类器的损失值计算中,它们才有意义。
————————————————————————————————————————
Softmax分类器为每个分类提供了“可能性”:SVM的计算是无标定的,而且难以针对所有分类的评分值给出直观解释。Softmax分类器则不同,它允许我们计算出对于所有分类标签的可能性。举个例子,针对给出的图像,SVM分类器可能给你的是一个[12.5, 0.6, -23.0]对应分类“猫”,“狗”,“船”。而softmax分类器可以计算出这三个标签的”可能性“是[0.9, 0.09, 0.01],这就让你能看出对于不同分类准确性的把握。为什么我们要在”可能性“上面打引号呢?这是因为可能性分布的集中或离散程度是由正则化参数λ直接决定的,λ是你能直接控制的一个输入参数。举个例子,假设3个分类的原始分数是[1, -2, 0],那么softmax函数就会计算:

现在看起来,概率的分布就更加分散了。还有,随着正则化参数λ不断增强,权重数值会越来越小,最后输出的概率会接近于均匀分布。这就是说,softmax分类器算出来的概率最好是看成一种对于分类正确性的自信。和SVM一样,数字间相互比较得出的大小顺序是可以解释的,但其绝对值则难以直观解释。
在实际使用中,SVM和Softmax经常是相似的:通常说来,两种分类器的表现差别很小,不同的人对于哪个分类器更好有不同的看法。相对于Softmax分类器,SVM更加“局部目标化(local objective)”,这既可以看做是一个特性,也可以看做是一个劣势。考虑一个评分是[10, -2, 3]的数据,其中第一个分类是正确的。那么一个SVM(\Delta =1)会看到正确分类相较于不正确分类,已经得到了比边界值还要高的分数,它就会认为损失值是0。SVM对于数字个体的细节是不关心的:如果分数是[10, -100, -100]或者[10, 9, 9],对于SVM来说没设么不同,只要满足超过边界值等于1,那么损失值就等于0。
对于softmax分类器,情况则不同。对于[10, 9, 9]来说,计算出的损失值就远远高于[10, -100, -100]的。换句话来说,softmax分类器对于分数是永远不会满意的:正确分类总能得到更高的可能性,错误分类总能得到更低的可能性,损失值总是能够更小。但是,SVM只要边界值被满足了就满意了,不会超过限制去细微地操作具体分数。这可以被看做是SVM的一种特性。举例说来,一个汽车的分类器应该把他的大量精力放在如何分辨小轿车和大卡车上,而不应该纠结于如何与青蛙进行区分,因为区分青蛙得到的评分已经足够低了。


