欢迎在文章下方评论,建议用电脑看
environment是未知的,不清楚做出了某个action之后会变到哪一个state也不知道这个action好还是不好,也就是说不清楚environment体现的model是什么,在这种情况下需要解决的prediction和control问题就是Model-free prediction和Model-free control。显然这种新的问题只能从与environment的交互得到的experience中获取信息。
将从某个起始状态开始执行到终止状态的一次遍历S1,A1,R2,…,Sk(状态,动作,回报)称为episode。已知很多的episodes。
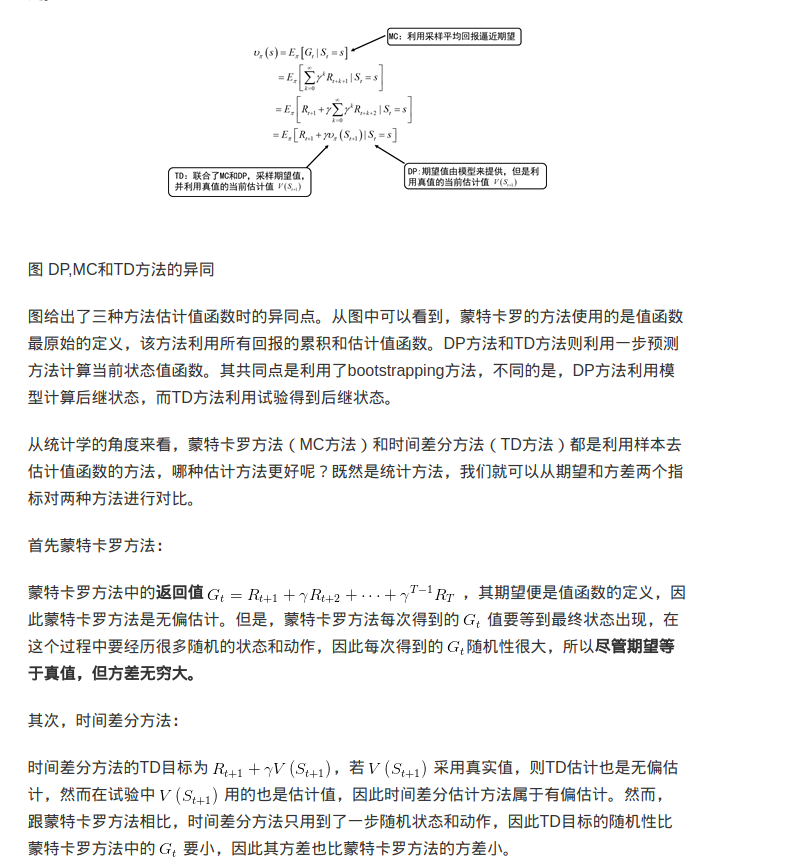
由于不知道智能体与环境交互的模型,蒙特卡罗方法是利用经验平均来估计值函数。能否得到正确的值函数,取决于经验。如何获得充足的经验是无模型强化学习的核心所在。
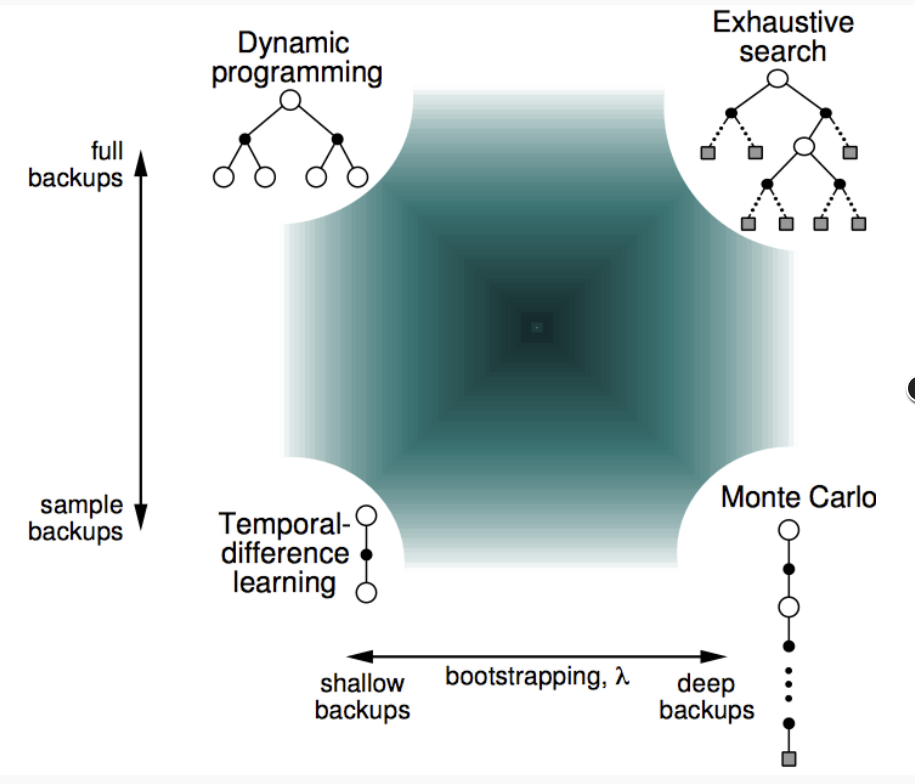
在动态规划方法中,为了保证值函数的收敛性,算法会对状态空间中的状态进行逐个扫描。无模型的方法充分评估策略值函数的前提是每个状态都能被访问到。因此,在蒙特卡洛方法中必须采用一定的方法保证每个状态都能被访问到。其中一种方法是探索性初始化。
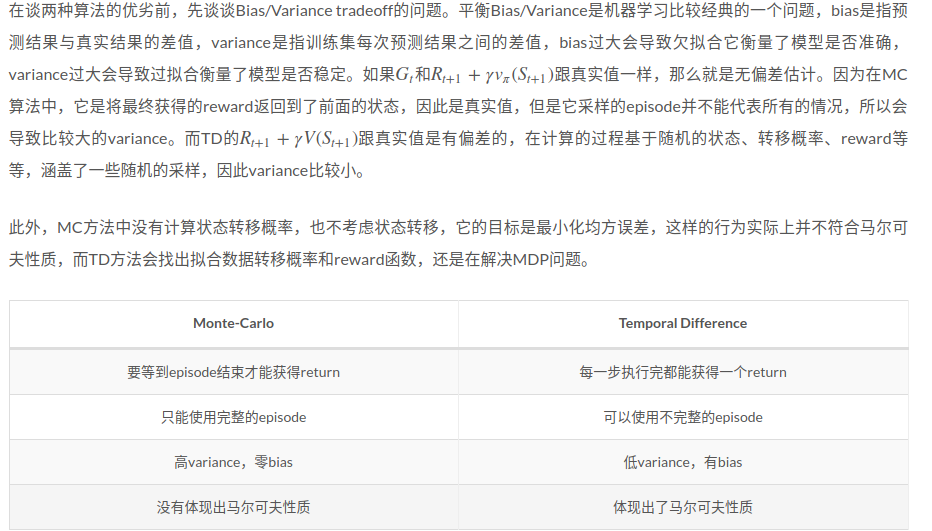
在我的理解看来,Prediction就是对策略的评估,然后要进行迭代评估,原因是agent在执行一次一个策略得到一个episode来评估是不能有效代表这个策略的期望价值的,只有多次迭代才能找到价值期望。同时有证明TD和MC方法都是可以收敛的。

最后说明,Prediction是一种在某种确定的策略下求值的方式,在课件中的21点的例子中,多次迭代才能求出值的原因就是一次的episode并不能求出值,而是多次的episode才能找出在这种策略下,这些状态的值。或者说,在求值的过程中,其实我们是在寻找那个状态到价值的那个参数,但仅仅一次或几次的episode,不能找到那个合适的参数映射,只有数据量很大的时候才能,当然是存在收敛的时候的!

我的理解是,一个是即时反馈,一个是完整的过程之后才反馈,视频中有一个撞车的例子,讲如果在开着车太快而差点撞上(没有撞上)迎面来的车的话,Temporal-Difference Learning会负反馈,就像告诉你不要开太快避免撞车,而Monte-Carlo Reinforcement Learning是不会有负面反馈的,原因是在本质上整个过程中没有撞车!
Temporal-Difference Learning可以找到正真的价值函数,Monte-Carlo Reinforcement Learning得到也是正真的价值函数,根据大数定律!