

欢迎在文章下方评论,建议用电脑看
强化学习是多学科多领域交叉的一个产物,它的本质就是解决“decision making”问题,即学会自动进行决策。在computer science领域体现为机器学习算法。在Engineering领域体现在决定the sequence of actions来得到最好的结果。在Neuroscience领域体现在理解人类大脑如何做出决策,主要的研究是reward system。在Psychology领域,研究动物如何做出决策,动物的行为是由什么导致的。在Economics领域体现在博弈论的研究。这所有的问题最终都归结为一个问题,人为什么能够并且如何做出最优决策。是怎么样找到最优决策的
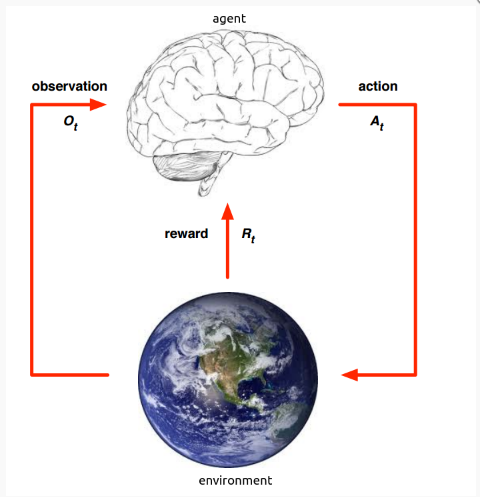

Goal: select actions to maximise total future reward
Actions may have long term consequences and reward that it may be better to sacrifice immediate to gain more long-term reward may be delayed
Examples:
A financial investment (may take months to mature)
Refuelling a helicopter (might prevent a crash in several hours)
Blocking opponent moves (might help winning chances many
moves from now)
在强化学习中,可以比作我们人和周围环境的交互,人在观察之后做出动作就会得到环境的相对应的反馈。而在强化学习中,我们就充当那个环境,我们给他一些数据给他观察,然后它做出动作,然后我们在制定一些反馈,随着时间的进行,模型就会越来越趋向于我们所想要的那样!
强化学习是一种试错(trial-and-error)的学习方式,一开始不清楚environment的工作方式,不清楚执行什么样的行为是对的,什么样是错的。因而agent需要从不断尝试的经验中发现一个好的policy,从而在这个过程中获取更多的reward。
在这样的学习过程中,就会有一个在Exploration和Exploitation之间的权衡,前者是说会放弃一些已知的reward信息,而去尝试一些新的选择,即在某种状态下,算法也许已经学习到选择什么action让reward比较大,但是并不能每次都做出同样的选择,也许另外一个没有尝试过的选择会让reward更大,即Exploration希望能够探索更多关于environment的信息。而后者是指根据已知的信息最大化reward。例如,在选择一个餐馆时,Exploitation会选择你最喜欢的餐馆,而Exploration会尝试选择一个新的餐馆。
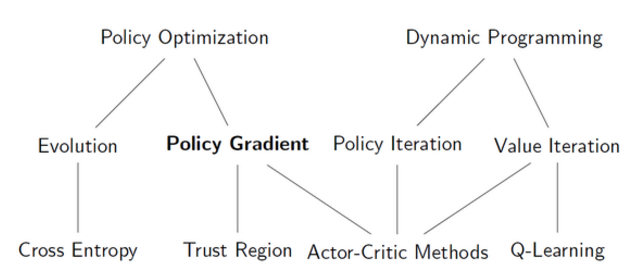
强化学习算法根据以策略为中心还是以值函数最优可以分为两大类,策略优化方法和动态规划方法。其中策略优化方法又分为进化算法和策略梯度方法;动态规划方法分为策略迭代算法和值迭代算法。策略迭代算法和值迭代算法可以利用广义策略迭代方法进行统一描述。
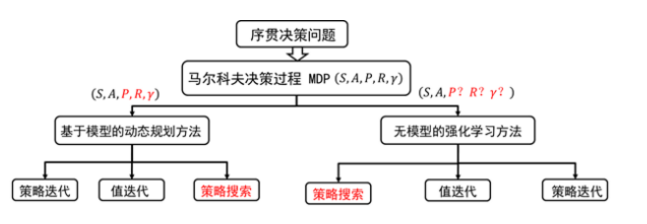
根据转移概率是否已知和某个动作是否好不好可以分为基于模型的强化学习算法和无模型的强化学习算法,如上图。
需要注意的是在一开始学的时候指迭代和策略迭代是base model的,也就是基于model的,而后面学习的蒙特卡洛树搜索或者其他base model是两个不一样的base model的,前者是实实在在的了解环境,在对环境有所了解的基础上(体现在知道p等)建模。而后者是用“想象力对环境进行建模”,也就是多出了一个虚拟环境。
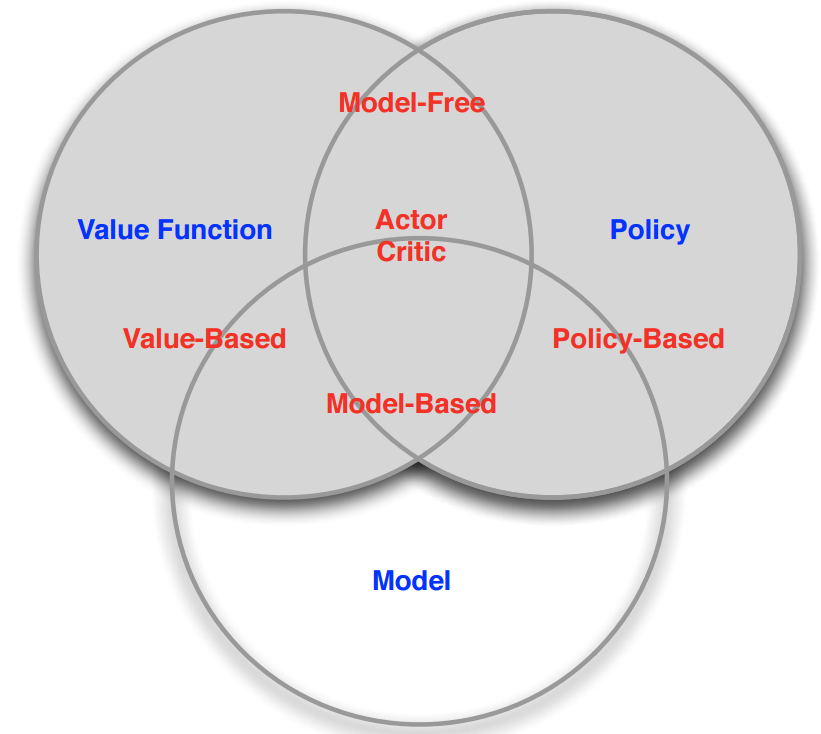
上面一图算是一个总结,也就是说根据model是否free分和以值函数和策略优化分是两回事,他们是有交叉的!
强化学习算法根据策略是否是随机的,分为确定性策略强化学习和随机性策略强化学习。另外,强化学习算法中的回报函数十分关键,根据回报函数是否已知,可以分为强化学习和逆向强化学习。逆向强化学习是根据专家实例将回报函数学出来


