

欢迎在文章下方评论,建议用电脑看
from now on,I will write my blog of the book(deep learning) in English,I am sorry that my English is so poor,but ,i will try my best
To extend linear models to represent nonlinear functions of x, we can apply the linear model not to x itself but to a transformed input φ(x), where φ is a nonlinear transformation. Equivalently, we can apply the kernel trick described in Sec. 5.7.2 , to obtain a nonlinear learning algorithm based on implicitly applying the φ mapping. We can think of φ as providing a set of features describing x, or as providing a new representation for x .

q:Why we need activation function?
a:

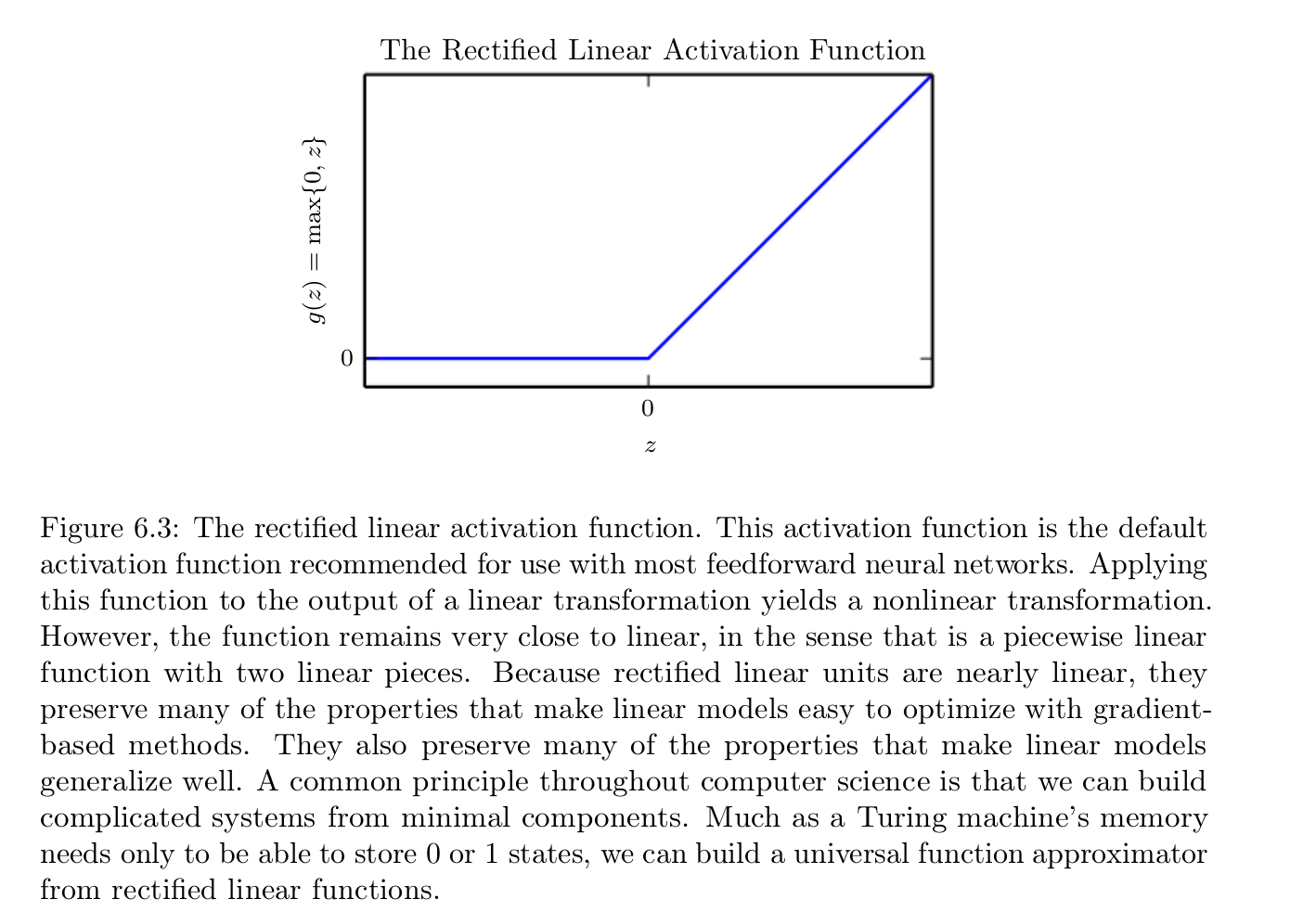
q:Why ReLU is the default activation function recommended for use with most feedforward neural networks.
a:
| mean squared error and mean absolute error often lead to poor results when used with gradient-based optimization. Some output units that saturate produce very small gradients when combined with these cost functions. This is one reason that the cross-entropy cost function is more popular than mean squared error or mean absolute error, even when it is not necessary to estimate an entire distribution p( y | x ) . |
Regularization of an estimator works by trading increased bias for reduced variance.
Before delving into the regularization behavior of different norms, we note that for neural networks, we typically choose to use a parameter norm penalty Ω that penalizes only the weights of the affine transformation at each layer and leaves the biases unregularized. The biases typically require less data to fit accurately than the weights. Each weight specifies how two variables interact. Fitting the weight well requires observing both variables in a variety of conditions. Each bias controls only a single variable. This means that we do not induce too much variance by leaving the biases unregularized. Also, regularizing the bias parameters can introduce a significant amount of underfitting. We therefore use the vector w to indicate all of the weights that should be affected by a norm penalty, while the vector θ denotes all of the parameters, including both w and the unregularized parameters.
也就是说,拟合权值w,是两个变量的交互,需要适应各种情况,而偏置不直接和输入数据相乘,它并不直接影响某一维度的数据,因此常常不用对偏置正则化
Their use as output units is compatible with the use of gradient-based learning when an appropriate cost function can undo the saturation of the sigmoid in the output layer.
In these chain-based architectures, the main architectural considerations are to choose the depth of the network and the width of each layer. As we will see,a network with even one hidden layer is sufficient to fit the training set. Deeper networks often are able to use far fewer units per layer and far fewer parameters and often generalize to the test set, but are also often harder to optimize. The ideal network architecture for a task must be found via experimentation guided by monitoring the validation set error.
Multi-task learning ( Caruana , 1993 ) is a way to improve generalization by pooling the examples (which can be seen as soft constraints imposed on the parameters) arising out of several tasks. In the same way that additional training examples put more pressure on the parameters of the model towards values that generaliz well, when part of a model is shared across tasks, that part of the model is more constrained towards good values (assuming the sharing is justified), often yielding better generalization.

A linear model, mapping from features to outputs via matrix multiplication, canby definition represent only linear functions. It has the advantage of being easy to train because many loss functions result in convex optimization problems when applied to linear models. Unfortunately, we often want to learn nonlinear functions.
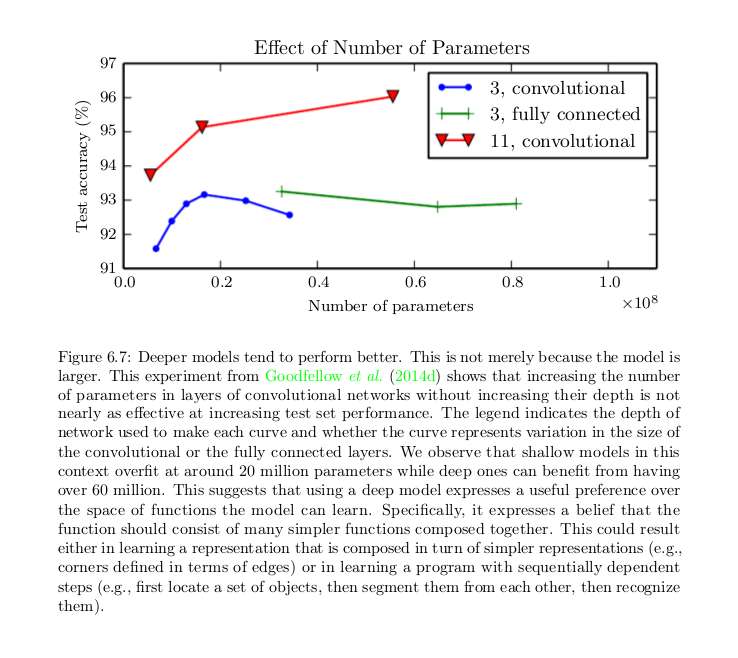
a feedforward network with a single layer is sufficient to represent any function, but the layer may be infeasibly large and may fail to learn and generalize correctly. In many circumstances, using deeper models can reduce the number of units required to represent the desired function and can reduce the amount of generalization error


