欢迎在文章下方评论,建议用电脑看
Recursive Neural Networks is indeed a superset of the previously discussed Recurrent Neural Network
The syntactic rules of language are highly recursive. So we take advantage of that recursive structure with a model that respects it!
递归神经网络通过在一个结构上递归地应用同一组参数来预测任意输入的结构, 或者通过遍历输入的拓扑结构产生一个标量输出来创建网络。 上篇文章介绍的循环神经网络可以看成时间上的递归, 可以看成是结构递归的一种简化版递归神经网络。
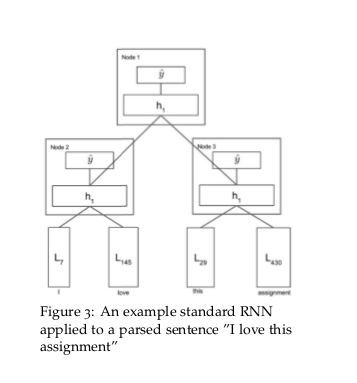
RNN适用于有嵌套层次和内在递归结构的任务。目前RNN在NLP领域的应用主要有句法分析和 句子表示。假设一个句子的含义是由句子中词的含义和词的组合方式决定的 ,word2vec已经一定程度上说明可以用向量来表示词的含义,词的组合规则从句法的角度 来看可以理解成句法树,我们可以通过遍历句法树来构建RNN(递归的时候使用同一组参数 )来生成句子的表示。这样生成句子、短语的表示考虑了词的顺序、词的组合和词的含义。 其实我们可以利用RNN来同时学习句子的句法结构和句子的向量表示。
RNN用于结构预测的时候需要用到一个max-margin标函数,暂时没有看懂这个目标函数。 所以本文仅介绍在有一个句法树的前提下来生成句子表示的过程,同时结合一个简单的情感 分析任务来解释RNN的前向传播和反向传播过程。
要解决下面的问题:
就是词的组合无限,我们是学不来全部词组的,现在我们要一种方式用有限的词向量来解决接近无限的自然语言处理问题,不过实践证明,Recursive Neural Networks是可以做到这一点的。

最简单的一个Recursive Neural Networks模型,需要注意的是,这的w是共享的,也就是说相同类别的一段文字,所用的w是一样的。但这很容易造成模型的capacity不强,文中有如下一段话:
using the same W to bring together a Noun Phrase and Verb Phrase and to bring together a Prepositional Phrase and another word vector seems intuitively wrong. And maybe we are bluntly merging all of these functionalities into too weak of a model.
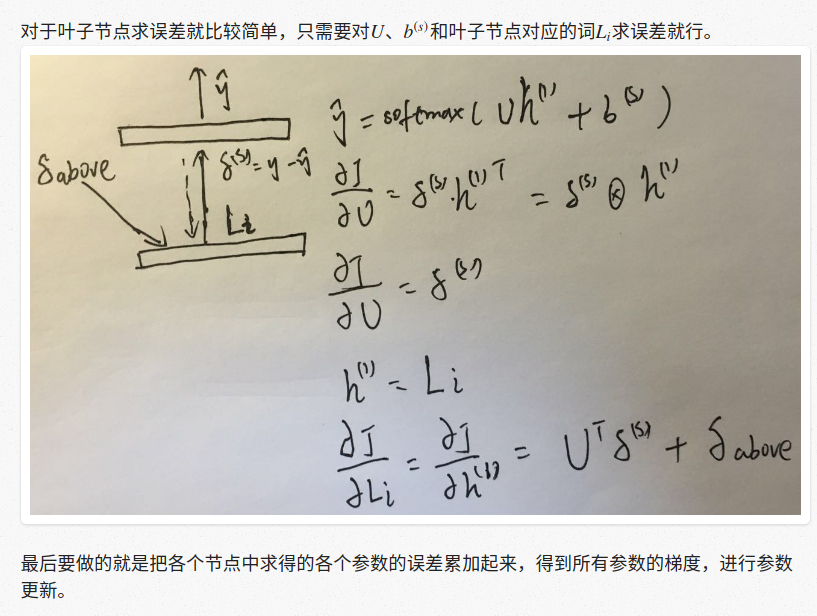
需要注意的是在RNN中我们在每个节点用的参数都是一样的,求导的时候和普通神经网络的区别 在于我们只需要把每个节点的参数的梯度累加起来就可以了。

整个后向传播过程也是一个深度优先遍历,步骤如下:
1.计算根节点的误差
2.计算左孩子的误差
3.计算右孩子的误差
下面以上节提到的情感分析的例子来描述一下整个后向传播过程。前文可知,RNN中每个节点 都进行了一次softmax分类,每个节点输出的情感分类的损失可以用交叉熵度量:

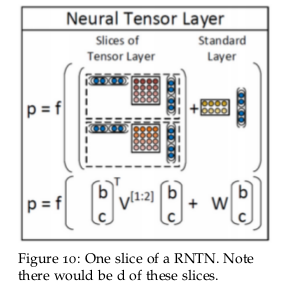
What we can do to remedy this shortcoming is to ”syntactically untie” the weights of these different tasks. By this we mean, there is no reason to expect the optimal W for one category of inputs to be at all related to the optimal W for another category of inputs. So we let these W’s be different and relax this constraint. While this for sure increases our weight matrices to learn, the performance boost we gain is non-trivial.
这个模型相对与上面一个模型在实际上有了很大的改进,就是不同的语法类别就用不同的w权重的规定,然后再boot他们的权重,这样肯定会学到更多,但也还是capacity不足。如下:

但需要说明的是,这个模型在在分类文本的时候还是有些时候不能有很好的capacity,具体如下:
By observing the errors the model makes, we see even the MV-RNN still can not express certain relations. We observe three major classes of mistakes.