

欢迎在文章下方评论,建议用电脑看
这些网络的要点是:有两个模型,一个是生成模型(generative model),一个是判别模型(discriminative model)。判别模型的任务是判断给定的图像看起来是自然的还是人为伪造的(图像来源于数据集)。生成模型的任务是生成看起来自然真实的、和原始数据相似的图像。这可以看做一种零和或两个玩家的纸牌游戏。本文采用的类比是生成模型像“一个造假团伙,试图生产和使用假币”,而判别模型像“检测假币的警察”。生成器(generator)试图欺骗判别器(discriminator),判别器则努力不被生成器欺骗。模型经过交替优化训练,两种模型都能得到提升,直到到达一个“假冒产品和真实产品无法区分”的点。
在训练的过程中固定一方,更新另一方的网络权重,交替迭代,在这个过程中,双方都极力优化自己的网络,从而形成竞争对抗,直到双方达到一个动态的平衡(纳什均衡),此时生成模型 G 恢复了训练数据的分布(造出了和真实数据一模一样的样本),判别模型再也判别不出来结果,准确率为 50%,约等于乱猜。这是双方网路都得到利益最大化,也就是不再更新自己的权重
网络示意:
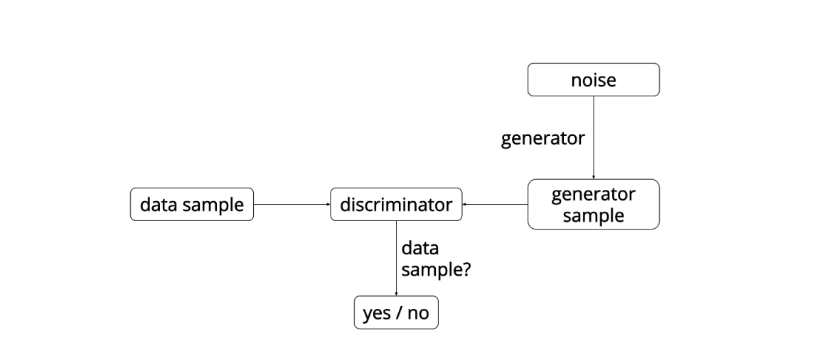
注:这里的G网络的输入是一个符合简单分布如高斯分布或者均匀分布的随机噪声。
算法流程:
给出下面的伪代码:
while equilibrium_not_reached:
# train the discriminator to classify a batch of images from our
# dataset as real and a batch of images generated by our current
# generator as fake
1.)
discriminator.train_on_batch(image_batch=real_image_batch,
labels=real)
2.)
discriminator.train_on_batch(image_batch=generated_image_batch,
labels=fake)
# train the generator to trick the discriminator into
# classifying a batch of generated images as real. The key here
# is that the discriminator is frozen (not trainable) in this
# step, but it's loss functions gradients are back-propagated
# through the combined network to the generator
# the generator updates its weights in the most ideal way
# possible based on these gradients
3.)
combined.train_on_batch(input=batch_of_noise, labels=real)
# where combined is a model that consists of the generator and
# discriminator joined together such that: input => generator =>
# generator_output => discriminator => classification
上面的过程简要如下:对于辨别器,如果得到的是生成图片辨别器应该输出 0,如果是真实的图片应该输出 1,得到误差梯度反向传播来更新参数。对于生成器,首先由生成器生成一张图片,然后输入给判别器判别并的到相应的误差梯度,然后反向传播这些图片梯度成为组成生成器的权重。直观上来说就是:辨别器不得不告诉生成器如何调整从而使它生成的图片变得更加真实。
理解了上面的之后,下面就是直接上数学式子了:
GAN模型没有损失函数,优化过程是一个“二元极小极大博弈(minimax two-player game)”问题:

这是关于判别网络D和生成网络G的价值函数(Value Function),训练网络D使得最大概率地分对训练样本的标签(最大化log D(x)),训练网络G最小化log(1 – D(G(z))),即最大化D的损失。训练过程中固定一方,更新另一个网络的参数,交替迭代,使得对方的错误最大化,最终,G 能估测出样本数据的分布。生成模型G隐式地定义了一个概率分布Pg,我们希望Pg 收敛到数据真实分布Pdata。论文证明了这个极小化极大博弈当且仅当Pg = Pdata时存在最优解,即达到纳什均衡,此时生成模型G恢复了训练数据的分布,判别模型D的准确率等于50%。
注意这里在介绍原始基本的gan,其实现在,这个价值函数已经发生很大的变化,如果从原理来说的话,就是用Wasserstein距离来量度真实分布和生成分布之间的差距,具体看这篇博文
DCGAN把上述的G和D用了两个卷积神经网络(CNN)。但不是直接换就可以了,DCGAN对卷积神经网络的结构做了一些改变,以提高样本的质量和收敛的速度,这些改变有:
DCGAN中的G网络示意:
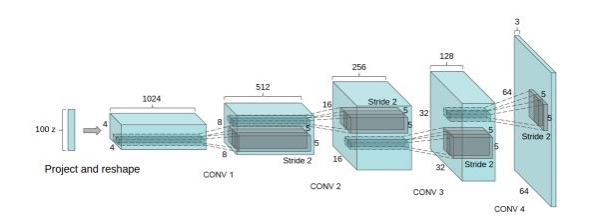
可以看出输入的是高斯分布的数据,最终生成图片,相等于卷积网络的逆过程。
最后说下GAN的优缺点-(翻译摘自知乎,Ian Goodfellow的原回答):

更多有关基础GAN的知识,详细查看paper-GAN



