

本文提出了一个基于神经网络的生成式问答模型(GenQA),该模型能够结合知识库信息,针对简单事实问句自动生成自然语言回答。GenQA模型基于序列到序列学习模型的编码-解码框架(encoder-decoder 框架),创新性的将问答任务与自然语言生成任务结合。本文基于结合知识库的问答对数据上进行了实验,实验结果表明GenQA能够处理问句的多样性问题,并且作出流畅的句式回答,相同数据集上效果优于其他对比方法。
GenQA模型由三个重要模块组成:Interpreter,Enquirer和Answerer。模型的整体框架见下图:
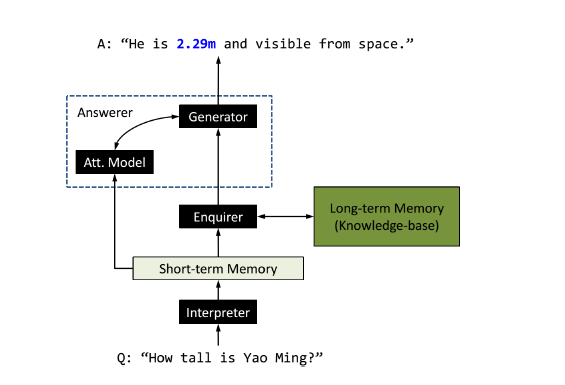
首先,Interpreter接收自然语言问句作为输入,采用带GRU的双向RNN模型,输出一个对问句的表示并存储在短时记忆中。在每个 t 时刻针对每个词向量xt ,会输出一个隐状态ht 。最终问句表示的长度即为句子长度,在每个时刻 t 包括了隐状态向量h,词向量x以及词自身的信息。问句表示将作为Enquirer以及Answerer的输入。
Enquirer的工作是根据知识库的长时记忆的知识以及输入的问句,获取正确的三元组。Enquirer首先使用简单的基于term-level的匹配在知识库中寻找合适的三元组候选,然后计算这些候选三元组与问题之间的相似度,归一化后将分数向量 r 作为Enquirer的输出:
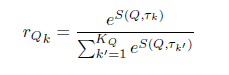
Enquirer模块中,本文提出了两种计算问题与三元组之间相似度的模型,第一种是双线性模型,相似度建模方式:
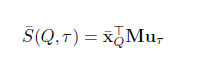
其中x表示问题序列中的词向量的均值,u表示三元组中subject与predicate向量的均值,M是要学的参数矩阵。这种模型记为GenQA。
另一种方法是基于CNN的模型,这种模型记为GenQA_CNN。
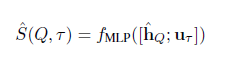
其中h为问句序列经过单层CNN后得到的向量表示,u表示三元组中subject与predicate向量的均值,两个向量拼接经过MLP得到最终的相似度得分。
Answerer接受上两个模块的输入,在知识库的指导下生成自然语言,如下所示:
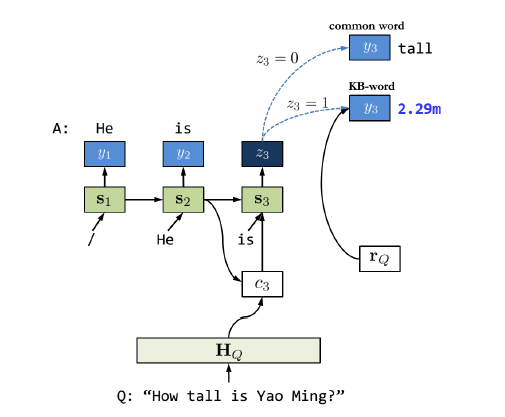
生成过程基于普通序列到序列模型的框架,使用RNN的decoder,在 t 时刻基于 (t-1) 时刻的隐状态、t 时刻的上下文向量(context vector)生成当前词。上下文向量是基于注意力模型从三元组和问句向量中学习到的。Answerer模块会使用一个逻辑斯蒂回归判断当前需要生成的是普通的词,还是知识库中的实体词,也就是三元组的object。逻辑斯蒂回归使用当前时刻隐状态作为输入,输出0时生成普通的词,生成普通词的模型与带注意力的序列到序列学习模型方法一致;输出1时,根据Enquirer模块的定长输出向量 r 作为输入,生成对应知识库三元组中的object词,注意这里是借鉴了copynet的做法


