

网络表示学习的典型思路是:先构建一个关于节点、关系表示的目标函数(能量函数或者损失函数),然后使用SGD等优化算法进行优化。最典型的算法是TransE,从TranE算法中又延伸出来了众多其他的算法,包括:TransH、TransR、PTransE、TransSparse、TransD。
translation的思想,即h的向量表示通过与r的向量表示进行一个操作可以近似得到r的向量表示。
这几年的研究不断扩展基于translation思想的知识图谱表示方法,在解决1对N、N对1之后,又考虑了关系路径、实体类型,链接预测、三元组分类等任务的效果得到不断提升。
TransE的算法使用了一个简单的线性运算构建目标函数,但是实验效果表明,TransE比之前一些涉及大量矩阵运算、非线性函数的方法效果更好。
假设网络图中的边表示为三元组(h,r,t),其中h、r、t分别是起始节点、关系、末尾节点的向量表示。TransE的学习目标是使得,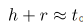 。使用
。使用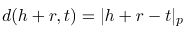 ,这里p可以取1或者2,也就是使用L1范数或者L2范数来表示损失。
,这里p可以取1或者2,也就是使用L1范数或者L2范数来表示损失。
TransE目标函数为:
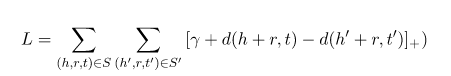
S’是通过对原来的三元组随机替换h或者t得到的噪声三元组。优化过程中采用了NCE(Noise Contrastive Estimation)思想,尽量使得噪声三元组的损失大于正确三元组的损失加上一个margin \gamma。
为了防止训练过程通过增大实体表示的norm大小来减少损失函数,这里限制所有的向量模长为1。
TransE使用同一个向量来表示同一种关系,难以体现1对多、多对多、多对1的关系中的多样性。因此TransH将关系表示为超平面(hyperplane,比整体空间少一个维度的子空间,例如三维空间中的二维平面)上的一个向量。也就是,弥补TransE上的不能一对多的缺陷。
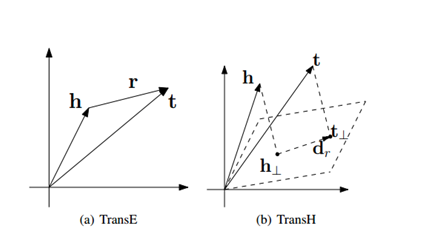
具体的做法就是
TransE和TransH将实体和关系都用同一个空间中的向量进行表示,TransR中实体和关系的表示位于两个空间。在计算损失函数的时候,先使用一个线性变化将实体的表示映射到关系表示空间,在计算损失函数。
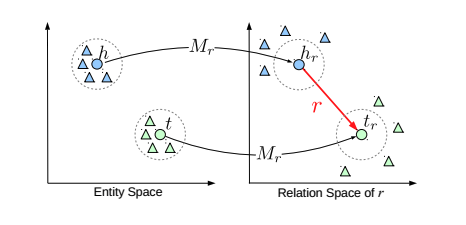
论文中还提出了一个CTransR。每个关系r对应于多个向量和映射矩阵,从而保证表示多样化的关系。先对关系r所连接的实体对进行聚类,每个类别c对应于一个向量表示。也就是说,这里是在适应两个实体间多种不同关系的情况。
这个是在TransR的基础上做了一个扩展。
与其他方法的比较:TransR方法中每个关系都对应一个投影矩阵,而TransD方法中投影向量是两个实体对应的向量与关系对应的向量组成,复杂度更低。TransH中每个关系对应一个投影向量,投影向量完全取决于关系,而TransD中,投影矩阵由实体与关系共同决定,具有更好的建模能力。
这个是在TransR上做了一个改进。
PTransE在学习向量表示的时候,不仅考虑了单独的关系,还考虑了路径信息。路径信息在某些情况下对于知识库的补全非常有用,例如从可以推测出关系。
这是一个好的表示方式,因为不止考虑到三元组的向量,还考虑到路径的向量。
TKRL(Type-embodied Knowledge Representation Learning)是考虑了实体类型的层次结构来学习知识图谱上的实体向量与关系向量。与TransD相同,TKRL先将实体与关系表示成向量,然后使用两个投影矩阵将实体向量投影到关系向量所在的空间。


