

本文针对的问题是开头说的多轮对话中response不一致的问题,这个问题很关键,多轮对话在工程应用中的意义更大,一致性是一个基础问题,解决不好,效果就会非常地差。本文针对这个问题,将user identity(比如背景信息、用户画像,年龄等信息)考虑到model中,构建出一个个性化的seq2seq模型,为不同的user,以及同一个user对不同的对象对话生成不同风格的response。
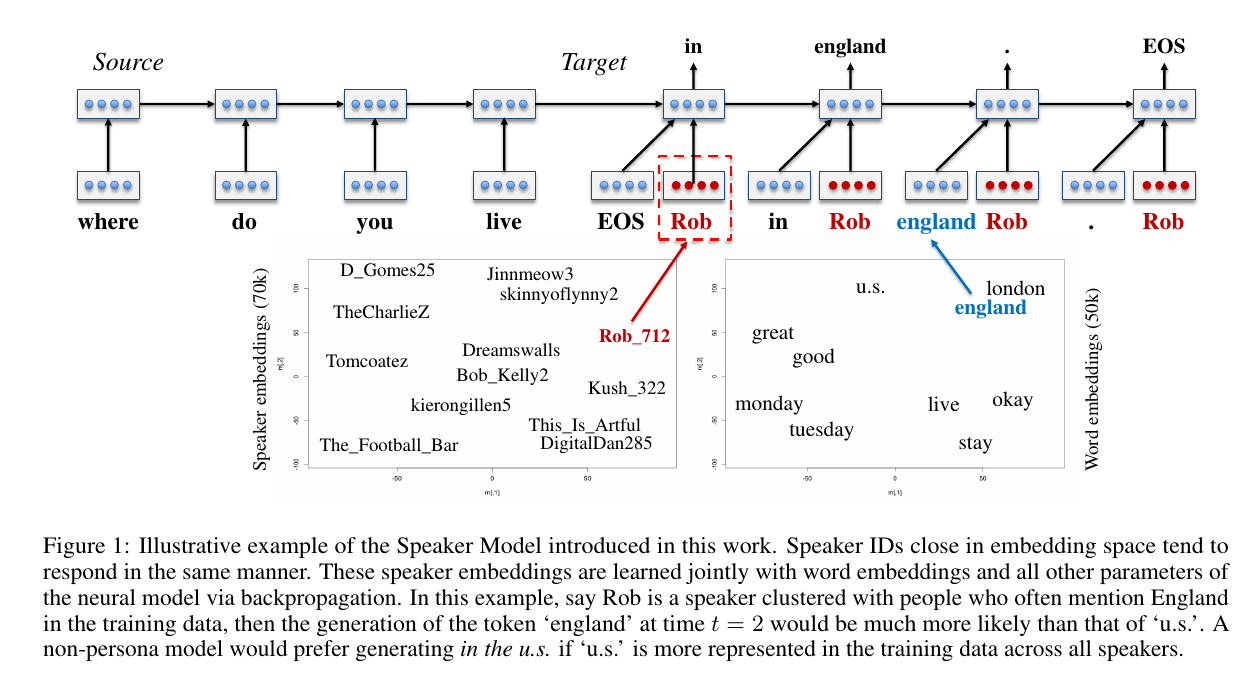
上图是Speaker Model的架构示意图,是一个典型的seq2seq模型,不同的地方在于在decoding部分增加了一个speaker embedding,类似于word embedding,只是说对用户进行建模。因为无法对用户的信息显式地进行建模,所以用了一种embedding的方法,通过训练来得到speaker向量,下面左边的图是speaker向量在二维平面上的表示,具有相似背景信息的user就会很接近,与word向量一个道理,注意这里的一个好处就是如果相近的user的其中一个的属性若在训练时没有现示的训练到,也会因向量相近而可以在测试的时候回答出(答案就是其相近的user一样即可)。decoding部分计算lstm各个gate用下式,vi表示speaker embedding,是在训练时通过反向传播训练。
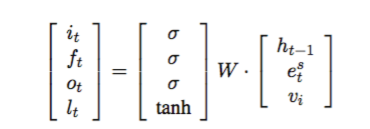
第二个模型是Speaker-Addressee Model,这个模型与上一个模型思想是一致的,只是考虑了一种更加细致的情况,在多人多轮对话(电视剧)中,每个人对不同的人说话style是不同的,所以应该在这类问题中需要考虑说话的对象,用V(i,j)来表示speaker i和j之间的这种关系,decoding部分计算如下式:
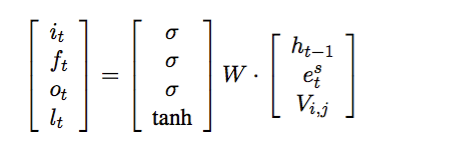
不足: 太依赖于数据集,能明确在特定位置加入keyword是很有局限的。


