

知识库问答(knowledge base question answering,KB-QA)即给定自然语言问题,通过对问题进行语义理解和解析,进而利用知识库进行查询、推理得出答案。如下图所示
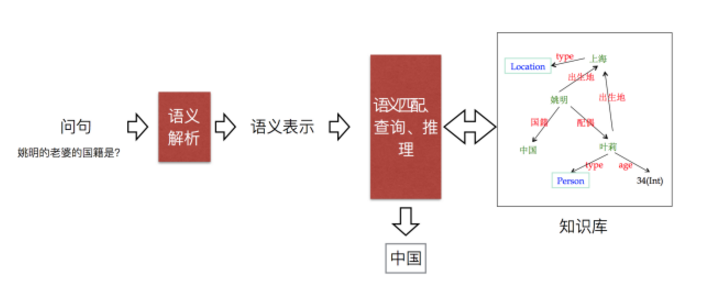
(注:该图片来自中科院刘康老师在知识图谱与问答系统前沿技术研讨会中的报告)
与对话系统、对话机器人的交互式对话不同,KB-QA具有以下特点:
答案:回答的答案是知识库中的实体或实体关系,或者no-answer(即该问题在KB中找不到答案),当然这里答案不一定唯一,比如 中国的城市有哪些 。而对话系统则回复的是自然语言句子,有时甚至需要考虑上下文语境。
评价标准:回召率 (Recall),精确率 (Precision) ,F1-Score。而对话系统的评价标准以人工评价为主,以及BLEU和Perplexity。
传统的主流方法可以分为三类:
语义解析(Semantic Parsing):该方法是一种偏linguistic的方法,主体思想是将自然语言转化为一系列形式化的逻辑形式(logic form),通过对逻辑形式进行自底向上的解析,得到一种可以表达整个问题语义的逻辑形式,通过相应的查询语句(类似lambda-Caculus)在知识库中进行查询,从而得出答案。
信息抽取(Information Extraction):该类方法通过提取问题中的实体,通过在知识库中查询该实体可以得到以该实体节点为中心的知识库子图,子图中的每一个节点或边都可以作为候选答案,通过观察问题依据某些规则或模板进行信息抽取,得到问题特征向量,也就是一个带有该问题特征的一个向量,建立分类器通过输入问题特征向量对候选答案进行筛选,从而得出最终答案。
向量建模(Vector Modeling): 该方法思想和信息抽取的思想比较接近,根据问题得出候选答案,把问题和候选答案都映射为分布式表达(Distributed Embedding),通过训练数据对该分布式表达进行训练,使得问题和正确答案的向量表达的得分(通常以点乘为形式)尽量高,得出最终答案。注意和信息抽取的不同在于这个方式是对候选回答和问题都进行向量建模,然后结合,得分最高的就为答案!
深度学习(Deep Learning):这本身并不是一类方式,只是其中的方法:比如使用卷积神经网络对向量建模方法进行提升,或者使用卷积神经网络对语义解析方法进行提升,或者使用长短时记忆网络(Long Short-Term Memory,LSTM),卷积神经网络(Convolutional Neural Networks,CNNs)进行实体关系分类。
现在比较常用的是使用记忆网络(Memory Networks),注意力机制(Attention Mechanism)进行KB-QA。
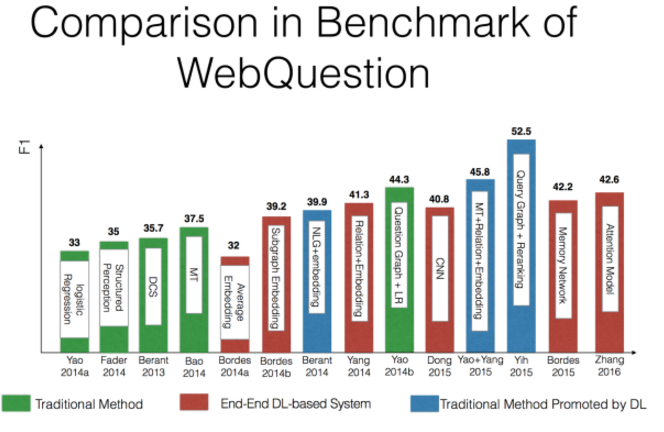
(注:该图片来自中科院刘康老师在知识图谱与问答系统前沿技术研讨会中的报告)
KB-QA问题的Benchmark数据集——WebQuestion。
该数据集由Berant J, Chou A, Frostig R, et al.在13年的论文Semantic Parsing on Freebase from Question-Answer Pairs中公开。
作者首先使用Google Suggest API获取以wh-word(what,who,why,where,whose…)为开头且只包含一个实体的问题,以“where was Barack Obama born?”作为问题图谱的起始节点,以Google Suggest API给出的建议作为新的问题,通过宽度优先搜索获取问题。具体来讲,对于每一个队列中的问题,通过对它删去实体,删去实体之前的短语,删去实体之后的短语形成3个新的query,将这三个新query放到google suggest中,每个query将生成5个候选问题,加入搜索队列,直到1M个问题被访问完。如下图所示
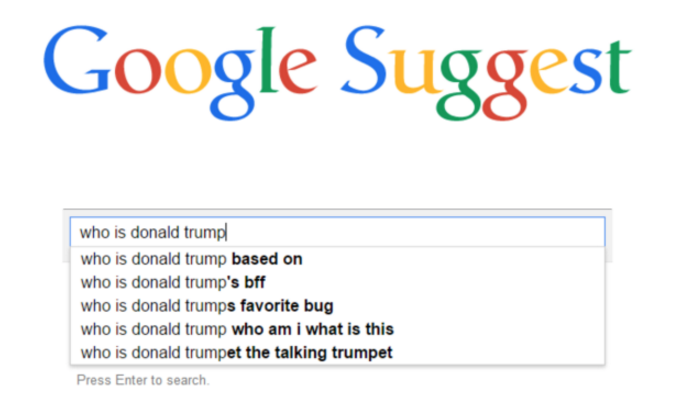
(注:该图片来自Google Suggest)
获取完问题后,随机选取100K个问题交给Amazon Mechanical Turk (AMT)的工人,让工人回答答案。注意,这里对答案进行了限制,让AMT的工人只能把答案设置为Freebase上的实体(entity),实体列表,值(value)或者no-answer。
最终,得到了5,810组问题答案对,其词汇表包含了4,525个词。并且,WebQuestion还提供了每个答案对应知识库的主题节点(topic node)。
可以看出WebQuestion的问题与freebase是不相关的,更加偏向自然语言,也更多样化。这里给出一些例子
“What is James Madison most famous for?”
“What movies does Taylor Lautner play in?”
“What music did Beethoven compose?”
“What kind of system of government does the United States have?”
该文章使用了卷积神经网络的一种变体(作者称为multi-column)从三个方面(答案路径Answer Path,答案上下文信息Answer Context,答案的类型Answer Type)对问题和答案的分布式表达进行学习,使得该分布式表达相比之前的向量建模方法能够包含更多有效的特征。
首先是对于问题的向量化。对问题的向量化,传统向量建模方法采用了类似词袋模型的方式,相当于它并未考虑问题的语言顺序(比如 “谢霆锋的爸爸是谁?” 谢霆锋是谁的爸爸? 这两个问题用该方法得到的表达是一样的,然而这两个问题的意思显然是不同的)。
对于这个缺陷,我们可以使用深度学习的模型对问题进行向量化,比如使用循环神经网络(Recurrent Nerual Networks, RNNs)、卷积神经网络(Counvoulutional Nerual Networks, CNNs )等模型提取问题特征,这样的方式考虑了语言的顺序,并且提取特征的能力也更加强大。
第二个缺陷是,在对答案进行向量化的时候,直接将答案的路径(问题主题词到答案实体的路径)和上下文信息(答案实体周围的知识库子图)一起作为答案特征,通过multi-hot的方式对答案进行向量化。事实上,这样的形式不利于模型区分答案的特征(仅仅根据答案的multi-hot向量是不好区分哪些是答案的类型,哪些来自答案的上下文,哪些来自问题主题词到答案实体的路径)。
因此我们可以将问题的特征表示拆解开,用三个向量分别表示答案的三个特征,即答案路径(Answer Path),答案上下文信息(Answer Context),答案类型(Answer Type),对于每一个答案特征向量,都用一个卷积网络去对问题进行特征提取,将提取出的分布式表达和该答案对应特征向量的分布式表达进行点乘,这样我们就可以得到一个包含三部分的得分函数:
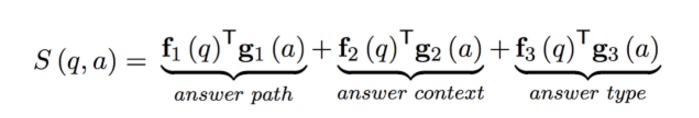
其中q代表问题,a代表答案,fi(q)代表问题经过卷积神经网络输出的分布式表达,gi(a)表示答案在对应特征下的分布式表达。
有了得分函数,我们就可以像向量建模方法一样,通过定义margin-based ranking损失函数对模型参数进行训练。
其整体思想是将知识库里的知识存储到记忆模块M中,问题经过输入模块I转化为分布式表达,输出模块O选择与问题最相关的支撑记忆(由于SimpleQustions的问题只依赖一个知识,所以只需要选择一条记忆),回答模块R将该记忆对应三元组的宾语作为最终答案输出。最后,为了测试记忆网络的泛化能力,在模型训练完毕后,我们将Reverb中提取的三元组,它的知识三元组是自然语言形式,如(“Obama”, “was also born in”, “August 1961”),知识三元组抽取自ClueWeb)作为新的知识,用泛化模块G将新知识存储到记忆模块中,在不经过re-training的情况下使用该记忆回答问题,测试模型的泛化性能。


