

文中描述的 TA-Seq2Seq 模型的核心思想是通过引入 LDA 模型结合 Seq2Seq 模型来产生更有信息含量、更为多样性及更话题相关的对话回答。
其采用的思路是在现有的带 Attention 的 Encoder-Decoder 模型架构上,通过 joint输入信息的 attention 和 topic attention来共同影响对话的回答的生成。
主要思路是意图通过引入先验知识到 Seq2Seq 模型来产生更高质量的回答。
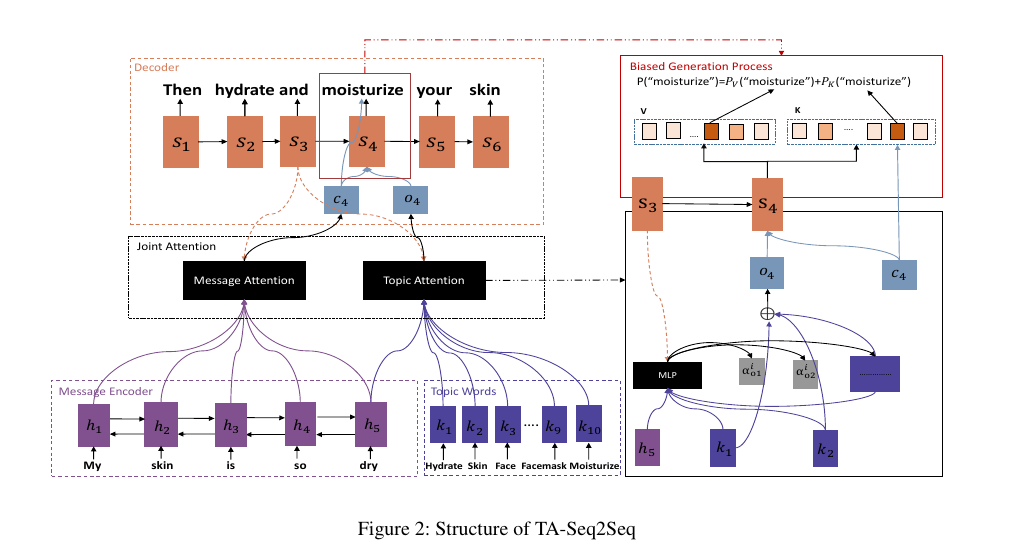
上图就是它的模型架构。说下它的实现思路:
topic 的获取
就是计算改topic下的词分布情况。
第一 步:获取 topic word 的 embedding vector 用新浪微博语料训练 TwitterLDA 模型,算法是 collapsed Gibbs sampling。消息输入后,模型给出所属 topic,取该 topic 下的 top100 作为消息的 topic words,删除通用词后,将这些 topic words 转为各自的向量表示。其中,每个 topic word 的向量是通过计算 topic word 在所有 topic 下的归一化频率得到的(文中 Eq. 4,,每个 topic word 对应的 vector 维度取决与 LDA 模型设置的 topic 数量;
第二步:通过 BiGRU 网络对输入消息做 encode得到一系列的hi;
根据第 1 步得到 input message 的 topic vector(也就是Ki),结合第 2 步得到的 last hidden state(也就是h5),通过 MLP 网络和 softmax 层得到 topic attention,即得到了各 topic word 的权重;
构造由 message attention 和 topic attention 联合影响的解码概率(文中 Eq. 6),该概率可突出 topic words 的作用。基于这个概率进行 token 解码;
与标准的 seq2seq+attention 模型相比,TA-Seq2Seq 模型的解码过程由 ci 和 oi 共同参与,特别地,在解码第 1 个输出 token 时,c0 插入了先验 topic 信息,因此本文模型可以提高首次解码的质量,从而对整个解码结果的质量产生正向影响。 百度贴吧数据集上的实验结果表明,本文提出的 TA-Seq2Seq 模型达到了 state-of-the-art 的效果,优于 Li Jiwei 提出的 Seq2Seq-MMI 模型。
Twitter LDA:
topic 和 topic word 是使用文中说的 Twitter LDA 在微博数据集上训练得到的,训练完之后每个 topic 实际上就是由词分布表示的,这里选择了词分布中概率最高的 100 个词作为这个 topic 的 topic words;2. 训练好之后,对于一个输入 X,可以根据这个模型判断 X 属于哪个 topic,然后选择对应的 topic words 送到后续的模型中产生 response。


