

提出来一种新颖的,完全有数据驱动的,并且基于背景知识(knowledge-grounded)的神经对话模型。该论文意在没有槽位填充下产生内容更加丰富的回应。论文实验中以对话记录和外部的“事实”为条件,通过常见的seq2seq方法使模型在开放领域的设置中变的通用和可行。在人工测评中,论文的方法相比传统的seq2seq能输出更加丰富的信息。
当前构建全数据驱动的对话模型所面临的的挑战是在已存在的对话数据库中,没有一个可以包括世界的所有知识。尽管这些数据库近年在不断的丰富,但和百科,评论或其他形式的数据相比还远远不够。
为了吸收为了向回复中灌输和对话上下文相关的事实信息,我们提出了一种知识场模型(如下图)。首先我们有一个可用的world facts,这是一个’原生’的文本实体(例如百科,评论),并以命名实体作为关键词进行索引。然后在给定的对话历史或者source sequence S中,识别S的“focus”(即特征词)。这些foucs可以被用于关键词匹配或更先进的方法中,例如实体链(entity linking)或命名实体识别。这样query就可以检索到所有上下文相关的facts: F = {f1, f2, f3, ….., fk}注意:这里检索到是一个fact是对应词袋的一个向量(但是这里的facts是句子)。最后将对话对和相关的facts都喂到神经架构中去训练。
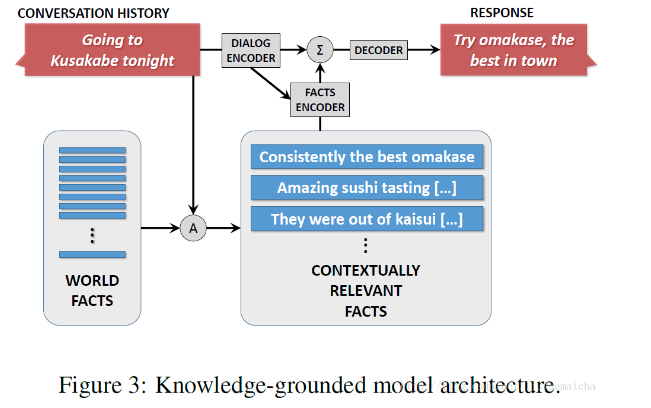
相比传统的seq2seq响应生成方法,这种知识场方法更具有综合性,因为它使我们关心的那些具有差异的实体不用去学相同的对话模型。()在实际中,即使给出一个在训练中没有出现过的实体(也就意味着在词典中也没有该实体),在这种情况下,我们的方法也能够依赖相关的facts来生成一个适当的响应。这也说明我们能够在不用重新训练整个模型的情况下通过facts来丰富我们的系统。
我们通过多任务并发式的学习方法将对话数据和场数据及少量的非正式交换(例如对“hi, how are you”的回应)自然的联系起来。其中的两种类型任务是我们多任务中最具特点的:
(1)一个纯粹的会话任务,该任务使用无fact encoder的(S,R)获得模型。其中S表示对话记录,R表示响应回复;
(2)另外一个任务使用({f1,….,fk,S},R)训练样例来获得最终的模型。
这种去耦合的两种训练条件有以下几种优势:首先,它允许我们先使用对话库来做预训练,再以预训练获得的模型为基础做多任务训练。再个,它能给我们灵活性的揭露不同类型的会话数据。最后,一个有趣的观点是可以在任务(2)中使用facts中的一条fact(R=fi)来替换响应,这就使得任务(2)更像一个自编码器(autoencoder),可以帮助模型产生更具丰富的内容。
模型中的Facts Encoder与记忆网络模型相似。记忆网络模型被广泛应用到QA中,通过保存在记忆中的事实来做推断。这篇使用组合记忆来塑造和一个指定问题相关的facts。在我们案例中,当一个实体在对话中被提到,那么就会基于用户输入和对话历史对facts进行检索和加权并最终生成一个答案。
在我们的适应性 记忆网络中,我们使用了一个RNN encoder将输入的sequence,注意在这里也就是query而不是facts转化为一个向量,而不是使用之前记忆网络中使用的词袋表示法。这能够使我们在输入的不同部分之间能够更好的利用词间的依赖性(inter lexical dependencies),并且能够使记忆网络模型(facts encoder)更加直接的适应Seq2Seq模型。
我们给出一个sentence集合S={s1,s2,s3,…..,sn}和一个fact集合F={f1,f2,…..,fk}。fact集合是和对话记录(即S)相关的。RNN encoder按token依次读入一条sequence,并更新它的隐藏状态(hidden state)。读入整条sequence后,RNN encoder的隐藏状态 u就是这条sequence的概要。通过使用一个RNN encoder, 我们可以获得源sequence更丰富的表示。 我们首先假设u是一个d维的向量,ri是fi的v维词袋表示。基于记忆网络,我们有:

(公式1,2,3是求解相关fact条目i的向量,公式4将所有相关facts向量整合,公式5是将相关的facts向量与encoder向量整合)
其中 A,C是记忆网络的参数。然后,不同于原来版本的记忆网络,我们使用了一个善于生成响应的RNN decoder。RNN的隐藏态使用u^来初始化,而u^整合了输入sequence和相关知识场,最后通过该隐藏态来预测响应sequence的逐词生成。
为了替代公式5中的求和方式,我们也实验了串联方式,但求和方式的效果更好一些。(Weston et al., 2014)的记忆网络模型可以看做是一个多层结构。在该任务中,我们只用到了一层,因为不需要多层次的归纳。


